
URLs are important in the digital marketing industry, especially in the field of SEO. URLs are the address of our online home – our website, which we want to rank in the top spot on Google for relevant queries. They are the face that we show to visitors we want to convert into paying customers.
Due to their crucial role, we at SEOptimer always place a large focus on creating properly optimized URLs that meet the highest search engine optimization standards.
As you may have noticed, we’ve also created an SEO-friendly URL checker that checks if a URL follows search engine optimization best practices.
Over the years, we’ve received numerous questions related to URL optimization and URL terminology. For this reason, we’ve decided to create a comprehensive guide covering the most frequently asked questions, intended to be an all-inclusive resource about how to create properly optimized URLs for SEO.
What is a URL?
A Uniform Resource Locator (URL) represents an address of a unique resource on the Web. In web browsers, the URL of a specific web page is displayed in the address bar at the top.

In theory, each URL points to one unique resource, which can include an HTML page, an image, a CSS document, etc.
They are most commonly used to reference web pages (http:// or https://), but also emails (mailto:), file transfer (ftp), database access (JDBC), and many more.
URL vs. Links
Before we go much further, we should distinguish the difference between a URL and a link. Although the two terms are often used interchangeably, it’s important to point out that a link is actually just a clickable snippet of text on a page associated with the URL it takes you to.
Do URLs have an Impact on Search Engine Rankings?
The answer to this question is not a straightforward “yes” or “no”. In 2017, Google already announced that using keywords in URLs has no significant impact on search engine rankings. John Mueller even went as far as calling keywords in URLs overrated.
Keywords in URLs are overrated for Google SEO. Make URLs for users. Also, on mobile you usually don't even see them.
— 🫧 johnmu of switzerland (personal) 🫧 (@JohnMu) March 8, 2017
However, with that being said, we still believe URLs play an important role in a page’s ability to rank for relevant queries in search engines. Here’s why:
URLs can Improve the Overall User Experience
Google is all about creating a pleasant user experience for its users.
Now, imagine the following two URLs:
- www.site.com/blog/social-media-management-tools
- www.site.com/blog/Social_media_managementtools_832i
So which URL do you think Google would prefer to rank in order to give users a good user experience?
URLs Tell Users What a Page is About
According to Moz, URLs are a minor ranking factor. With that being said, URLs are still used by search engines and humans to get an understanding of what the on-page content is about.
You can almost think of URLs as the “cherry on top of the cake” - although they don’t make a huge difference in the taste of the cake, they still add a nice touch to the overall experience.
Likewise, creating properly optimized URLs won’t magically cause your content to rank, but they do have a role in indicating what the user can expect to find on the page.
How to Create Properly Optimized URLs for SEO
A good URL structure allows users and search engines to connect the dots of your website logically and crawl the pages more easily. As stated, it can significantly improve user experience and enhance your SEO efforts.
While we’ve already scratched the surface of this topic, there are many other practices that need to be implemented to help you reduce bounce rate, improve dwell time and accelerate your rankings.
English-Like, User-Friendly Structure
The very first step in creating properly optimized URLs for SEO is to strategically plan your site’s URL structure before you even start your website setup.
The most important principle is that a URL structure follows the navigation you’ve established, but here are a few additional points to keep in mind:
- Make it logical. Simplicity will be appreciated both by users and search engines. First, create the most important categories, and then move on to subcategorizing in the way it seems most logical based on your website content.
- Keep the number of categories as low as possible. This, of course, does not apply to large eCommerce websites that sell a variety of items, but even they have to be organized logically into separate categories. An average business or personal website should keep the number of categories somewhere between 2 and 7.
- Create a shallow navigation structure. What this means is that none of your pages should be buried deep into the structure but should be easily accessed in no more than 2 or 3 logical clicks.
Sitelinks
Sitelinks are direct links to your sub-pages, shown in a Google search result. They are meant to help users navigate to website content faster. Google automatically generates these based on what they think will be most relevant to searchers.
You can’t control these directly, but to maximize the quality of sitelinks that are shown, make sure any links within your site to internal pages have a good anchor or alt text that’s informative and succinct.
Internal Linking
Internal links will help establish the hierarchy of the website, spread link juice and enable users to navigate the website with ease. Ensure anchors contain the same keywords as URLs of the pages you are linking to.
Keyword Mapping
This is an entire science of its own, but generally, you would want to optimize your pages, and subsequently their URLs to reflect keywords you want to rank for.
You would determine these keywords through a detailed keyword research process to identify opportunities, then structure your page content and URLs to reflect these opportunities.
Use of Keywords in URLs
Using relevant keywords (that you’ve chosen via a keyword mapping process) in URLs helps indicate to both search engines and users what the page is about.
There are three rules to live by when adding keywords to create properly optimized URLs:
- Match the URL with the title of the page. Just to be clear, we don’t mean to aim for a 100% match, but just enough to indicate what the page is about. This matters, because most users simply glance at a URL to make assumptions regarding the content of the page. If it doesn’t meet their expectations, they decide to leave abruptly, leaving you with a higher bounce rate.
- Target 1 or 2 keywords per URL. If a website is properly structured, that means that a single page revolves around a single product/service or at least a group of related products or services. In that case, you should be able to dedicate no more than two keywords that would describe what the page is about and would be included in the URL. Anything more than that could cause confusion with search engines, which will in return affect your rankings for relevant queries.
- Don’t stuff your URLs. In the past, when search engines were simpler, website owners could try to ‘stuff’ particular keywords repeatedly into URLs, or other page elements to maximize rankings. This doesn’t cut it anymore, and you need to ensure that this content appears natural and not manipulative.
Use of Characters
In order for a URL to be properly optimized, readable, and easy to understand, you have to make a strategic choice of characters.
A variety of strange symbols and numbers can confuse users and make the URL less memorable.
Take a look at the three URLs – which one do you trust the most?
- https://www.seoptimer.com/seo-services
- https://www.seoptimer.com/post?ID=77&kw=seo+services
- https://cdn07.seoptimer.com/ post?ID=77&kw=seo+services
It’s not just strange characters that should be avoided though. Here are a few other guidelines:
- Use alphanumeric characters where possible.
- Skip punctuation and other unsafe characters. Certain characters are difficult to read and can make URL comprehension impossible. Check out the complete list on Perishable Press.
- Use only lowercase characters. Although this doesn’t apply to Microsoft users, those who work with Linux/UNIX will land on the 404 page if they choose to capitalize certain characters in the URL.
- Stop words are not necessary. Stop words are the most common words in a language, and search engines are programmed to ignore them. As such, they can be excluded from URLs.
- Use hyphens and not underscores. This reflects more advice provided by Google, as hyphens have been shown to be easier on the eye, and, whenever there’s an underscore between words, Google chooses to combine the two words as if they are written without a separator of any kind. To put it simply – hyphens help improve your SEO score.
URL Length
Google advises its users to keep their URLs as simple and as intelligible to humans as possible. Shorter URLs are easier to remember and share, meaning that cutting down on their length may improve the shareability of your content.
Once you go over 512 pixels (64 characters) Google will prune your URL in search results. Sometimes it can make sense to use an URL shortener service to minimize your URL length, and increase shareability.
Redirects and Canonicalization
Having duplicate content on your site can create problems with search engines. Thus, if you notice the same or similar content pieces published on two different URLs, opt for either the 301 redirect or rel=canonical as we’ve discussed previously.
It is also highly advisable to use 301 redirects when transferring HTTP to HTTPS, as less than 5% of the top 10,000 websites currently redirect users automatically.
Secure URL Structure
Although the primary purpose of SSL was to secure user data, this has since become a ranking signal, and as Chrome is about to label all non-HTTPS sites as not secure, it will help build trust with users.
With Chrome currently holding almost 60% of the market share, not implementing SSL correctly is a problem you should avoid at all costs.
Importance of a Clean URL Structure
Creating properly optimized URLs for SEO entails writing clean URL structures. URLs should look as clean, simple, and short as possible.
The reason for this is that clean URLs build a certain level of trust with website visitors. The last thing you want to be doing is chasing away valuable traffic just because of a badly written URL.
So, what do we mean by a “clean” URL structure? Simply, a clean URL structure is one that follows these guidelines:
- Is easy to read.
- Don’t contain strange characters. (see below)
- Is related to the on-page content and can be used to determine what the content is about.
- Only uses lowercase characters.
- Doesn’t contain stop words.
Elements of the URL Structure
It’s useful to consider a URL as nothing more than a regular postal mail address. Check out the image below to get a better understanding of URL structures.

Now, let’s get more technical and break down the different URL segments. Each URL consists of mandatory and optional parts:
Mandatory URL Parts
Protocol
This is the first part of a URL that indicates the protocol a web browser has to use, and it represents a defined method for transferring or exchanging data via a computer network.
Historically, HTTP was the most commonly used protocol, but due to search engine algorithm changes and new industry demands, the more secure version called HTTPS dominates the web now.
Aside from the two, mailto: for opening a mail client and ftp for handling file transfers can also appear in your address bar.
Domain Name
Domain names are an entirely separate science that we’ll delve into in another blog post, but in summary, they are a name reference to a web server that serves web pages.
A domain name is mapped to a server using a server’s IP address and the Domain Name System (DNS).
There are a huge variety of domain names that you can choose for a site, but in general, it’s better to keep them short and memorable.
Subdomain
A subdomain is a subset of a larger domain. It is displayed before the first dot (.) in a domain name, which in the majority of cases is www.
It is possible to use any word to create a unique web address without having to change your domain name. A subdomain is an extension of a registered domain name and it allows you to send website visitors to a different web address or point to a specific web address or directories in your hosting account.
The majority of webmasters use subdomains to organize their websites into sections according to specific niches, but you can also take advantage of a certain subdomain to separate the blog or eCommerce sections of your site from the main one.
Some webmasters also use subdomains to develop a separate website for mobile devices only.
Path to file
In the past, a path indicated a physical file location on the Web Server. Now, we can say that paths are an abstraction handled by web servers, that point to particular pieces of content.
Optional URL Parts
To better analyze the parts of a URL that are usually omitted, we’ll provide the following example.
TLD
A TLD, or a domain extension, follows the last dot (.) in a domain name.
The .com TLD takes the lead with more than 80 million extensions worldwide, while in general, the top 10 extensions are country-specific TLDs, such as .de that’s used in Germany, .cn for websites in China, and .uk that’s commonly used in the United Kingdom.
So how do you choose the domain extension that will benefit your online branding efforts the most?
Let’s take a brief look at some of the most popular domain extensions and their characteristics:
- .com – Although it was originally derived from the word ‘commercial’, and focused on ‘for-profit businesses’, today it is widely used by both personal users and businesses of all sizes, niches, and types.
- .net – Similar to .com, this TLD is available for everyone. Initially, it was reserved for networks and internet service providers, but now it is a great .com alternative, especially for application- and tech-based companies, since many users associate it with technology.
- .org – At first this TLD was used by non-profit organizations, but today it is a popular TLD for many non-governmental organizations, politicians, and political parties.
- .gov – This particular domain extension is reserved solely for government agencies.
- .edu – Only educational institutions are able to acquire the .edu domain extension.
- .info – Short for ‘information’, .info is an open TLD available for all users.
- .xyz – Like .info, it is available for general use.
- .ly – Although it is a Libyan country code, we’ve seen numerous startups taking advantage of .ly to create creative, catchy, and punny domain names.
Recently, there have been a great number of new domain types to hit the scene such as .accountants and .technology. We would generally recommend steering to the main ones, but sometimes these can make a good alternative when the .com TLD is not available.
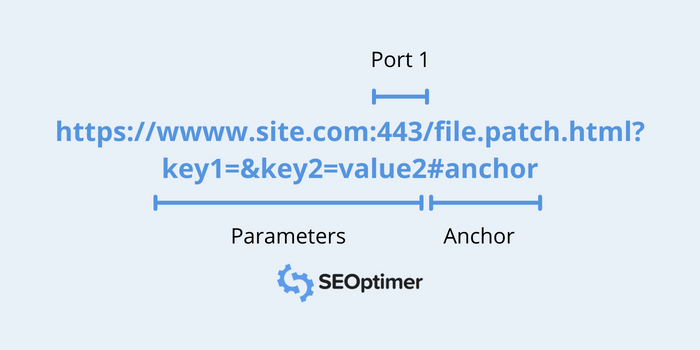
Port
A port is a part of a URL that is usually omitted. It can be called a gate that is used to access the resource on the web server, and it differs based on the protocol that is used (for instance, port 443 is for https, and 80 for http).
You can choose to explicitly include the port, but if it is not included, it will default based on the protocol chosen (http or https).
File Name
Historically, most websites would be shown by referring to specific file names. These days, the actual files being read by a web server are abstracted from users, so it is less frequent and not recommended to show filenames.
Parameters
Parameters are a list of value/key pairs that are separated in a URL with the “&” symbol.
They are used by web servers to complete certain actions before returning to the source. Often pages that include things such as contact forms, may use these parameters to send details to another page.
Anchor
Using the “#” character, you can point to a specific part of the webpage. In a way, it enables you to bookmark a certain part of the document, giving your browser directions on where exactly on the page should users should land.
Trailing slash
Trailing, or a forward slash, is used in a URL to mark a directory, and it is placed at its very end. The absence of a trailing slash used to mean that that URL takes you to a file, not a directory, but this is no longer the case.
If a webpage can be opened with more than one or no trailing slashes, Google may consider multiple indexing of the same webpage as duplicate content and mark it as spam.
Furthermore, multiple indexing can result in the division of incoming traffic, which additionally affects your rankings.
Whether or not you will be using a trailing slash is not important, as long as you’re consistent with it. You can use the canonical tag or 301 redirects to direct users and search engines to the preferred version.
Characters Used for Structuring URLs
There tends to be a lot of confusion about which characters can be used in an URL. Below, we differentiate:
Reserved set of characters
This is the most commonly used set of characters. Each character carries a specific meaning to web servers:
; | / | ? | : | @ | & | = | + | $ | ,
Unreserved set of characters
This set of characters doesn’t need to be encoded/escaped when included as a separate part of a URL:
– | _ | . | ! | ~ | * | ‘ | ( | )
Unwise set of characters
As the name suggests, it is not wise to use them in a URL, since they can be modified by gateways or used as delimiters in some cases:
{ | } | | | \ | ^ | [ | ] | `
Excluded set of characters
The excluded set is made up of all ASCII control characters, a space character, and the following group of characters:
< | > | # | % | “
These should be escaped, except for some which can have a special meaning in a specific context. For instance, you may have noticed that we’ve already mentioned “#” when we talked about URL parts, where this character’s purpose is to refer to a specific location in a document.
URL Categories – Absolute and Relative URLs
Absolute URLs contain all the necessary information to locate a certain resource (though protocol and port are optional elements and don’t need to be included).
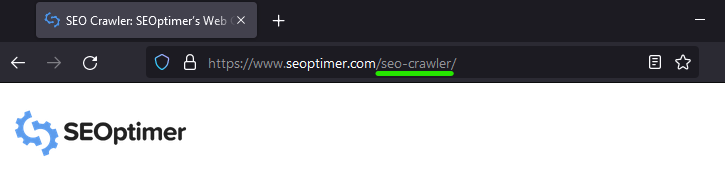
When it comes to relative URLs (which would in our case be /seo-crawler), as their name indicates, they are always interpreted as relative to another URL, known as the base URL.
They are most commonly found in HTML documents. To convert a relative URL into its absolute form, it can be explicitly specified in the document using HTML <base> tag, and if not, then we treat the URL of the document as the base for that relative URL.
URL Types
URLs are classified as dynamic and static, the latter being more SEO-friendly.
Dynamic URLs
This type of URL is often a result of a search, product, or category page retrieved from a database.
They are considered less search engine- and user-friendly, as they tend to contain unintelligible characters which make it difficult to understand the purpose of a specific page.
As such, dynamic URLs don’t get indexed as quickly as static ones and can be considered spammy.
Static URLs
When a web page has a static URL, it means that its content is generally fixed. Static URLs contain mostly alphanumeric characters and usually include relevant keywords, thus indicating what the content of the page is about.
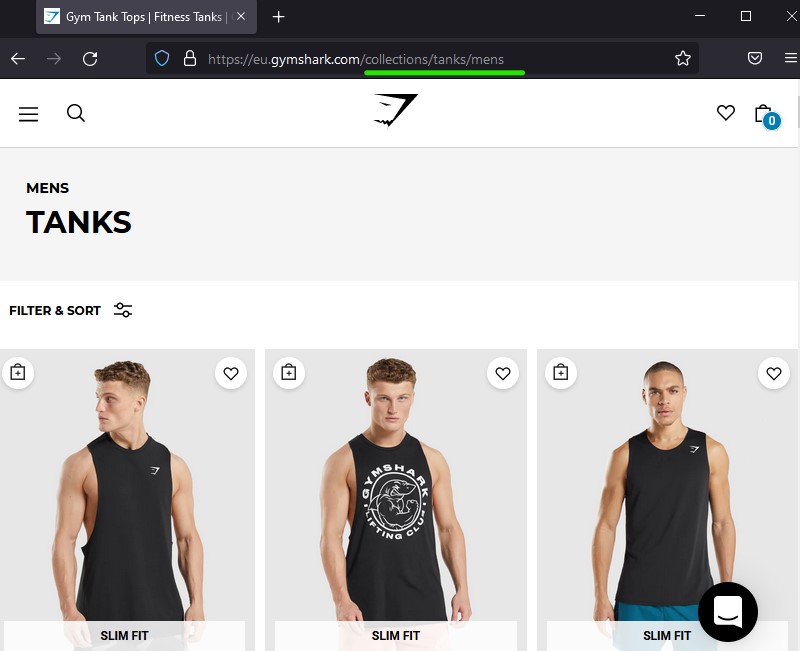
Static pages tend to get indexed faster, rank higher, and enjoy a greater CTR. Just think about it, which of the two would you prefer:
https://www.seoptimer.com/seo-crawler
Or
https://www.seoptimer.com/index.php?page=seo/crawler
HTTPS vs HTTP
In August 2014, Google officially announced that transferring a website from HTTP to HTTPS protocol would produce ranking benefits.
So, what’s the difference between the two? They are both hypertext transfer protocols, right?
True, but as search engines are working in an effort to improve user experience, it was decided to add an additional line of security (HTTPS).
But let’s explain both protocols in greater detail so you can understand why Google decided to mark HTTP websites as unsecure and include SSL as one of its ranking factors.
- HTTP – Hypertext Transfer Protocol represents a system for transmitting and receiving information across the Internet. However, as it is an application layer protocol, its focus is merely on the successful presentation of information to the user, not on how the data is transferred. This means that it doesn’t pay extra attention to the security of your data.
- HTTPS – Secure Hypertext Transfer Protocol was developed to allow authorization and secured transactions. It works in conjunction with the Secure Sockets Layer (SSL) protocol to transport your data safely. Taking that into consideration, it’s no wonder Google uses HTTPS as a ranking signal and prefers websites that encrypt user data for an additional layer of security.
While HTTPS and SSL have been used interchangeably, they are not the same thing. SSL represents the standard security technology that establishes an encrypted link between a browser and a web server.
HTTPS is a secure protocol because it utilizes this technology. However, it is no longer just another ranking signal. Effective July 2018, Google’s Chrome browser will mark all sites which don’t implement SSL certificates as “not secure”, which makes the transfer from HTTP to HTTPS an imperative.
 Image source: EFF.org
Image source: EFF.org
Status Codes
A status code can be referred to as an online conversation between the server and a browser.
The information they send to one another revolves around the status of the request. To put it simply, the discussion is largely based on whether everything is OK or not.
To be more technical, an HTTP status code is a server’s response to a browser’s request.
There are several classes of status codes, but for now, we are going to focus on status codes that are crucial for SEO experts.
Status Code 200
This is an ideal status code for a functioning page.
301 Redirect
This status code refers to a permanent redirect to a different URL. A 301 redirect means that everything, from users and bots to link equity will be passed on.
Nevertheless, note that not all redirects are treated equally, and 301 still remains the preferred method.
302 Redirect
Status code 302 is a temporary redirect and is, for instance, highly beneficial for eCommerce websites that wish to indicate an ongoing sale or discount offer.
This status code is not recommended for permanent changes, as it doesn’t tell search engines to pass link equity.
Status Code 404
The 404 error means that the page cannot be found by the server. However, it is uncertain whether it is because the page doesn’t exist, or it has been removed temporarily or permanently.
Practices for handling 404 errors are different – some decided to use 301 redirects and navigate users to the most relevant page, while others leave them.
Canonical Tags
From an SEO perspective, canonical tags are similar to 301 redirects. Both indicate that multiple pages should be considered as the same page.
Nevertheless, certain crucial differences need to be pointed out:
- 301 redirects forward all traffic (bots and users) to a different URL, while canonical tags only redirect bots.
- A 301 redirect can be applied across different domains, and canonical is applicable only to one website.
- The 301 is a much stronger signal that multiple pages have a single source.
The reason you may opt for canonical instead of a 301 redirect is if you have an old branding element you want your users to see, but when it comes to search engines you want to indicate that out of the two pages, you would prefer the new one to be ranked.
Just like a 301 redirect, a canonical tag doesn’t pass on all link juice, but only some of it.
Conclusion
The information provided in this article has been collected from years of experience working with websites, and URLs specifically – helping our users make the most of their websites.
I hope you’ve enjoyed this guide on URL optimization best practices, and if you have any additional questions, feel free to reach out to us via Livechat or Twitter.










