Hvis du modtog advarslen ‘Indekseret, men blokeret af robots.txt’ notifikation i Google Search Console, vil du gerne rette det så hurtigt som muligt, da det kan påvirke dine siders evne til overhovedet at rangere i søgeresultatsider (SERPS).
En robots.txt-fil er en fil, der ligger i din hjemmesides bibliotek, som giver nogle instruktioner til søgemaskinecrawlere, som Googles bot, om hvilke filer de skal og ikke skal se.
‘Indekseret, men blokeret af robots.txt’ indikerer, at Google har fundet din side, men også har fundet en instruktion om at ignorere den i din robots-fil (hvilket betyder, at den ikke vil vises i resultaterne).
Nogle gange er dette forsætligt, eller noget er det utilsigtet, af en række grunde beskrevet nedenfor, og kan rettes.
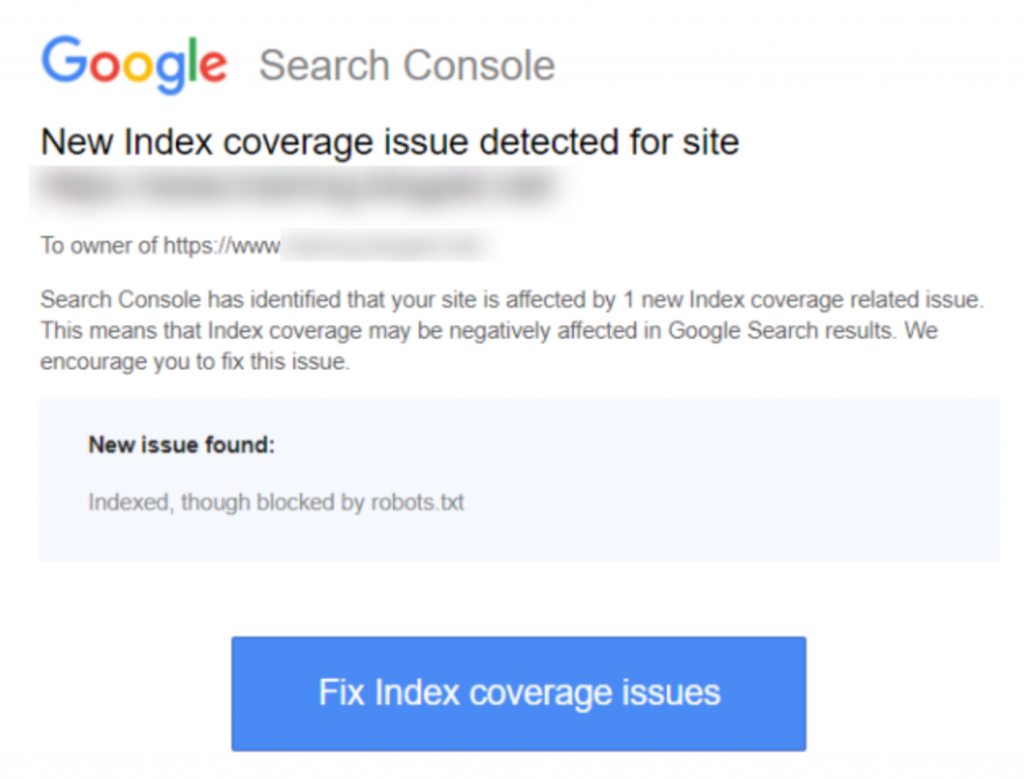
Her er et skærmbillede af meddelelsen:
Identificer den berørte side(r) eller URL(er)
Hvis du modtog en notifikation fra Google Search Console (GSC), skal du identificere den pågældende side(r) eller URL(er) i spørgsmålet.
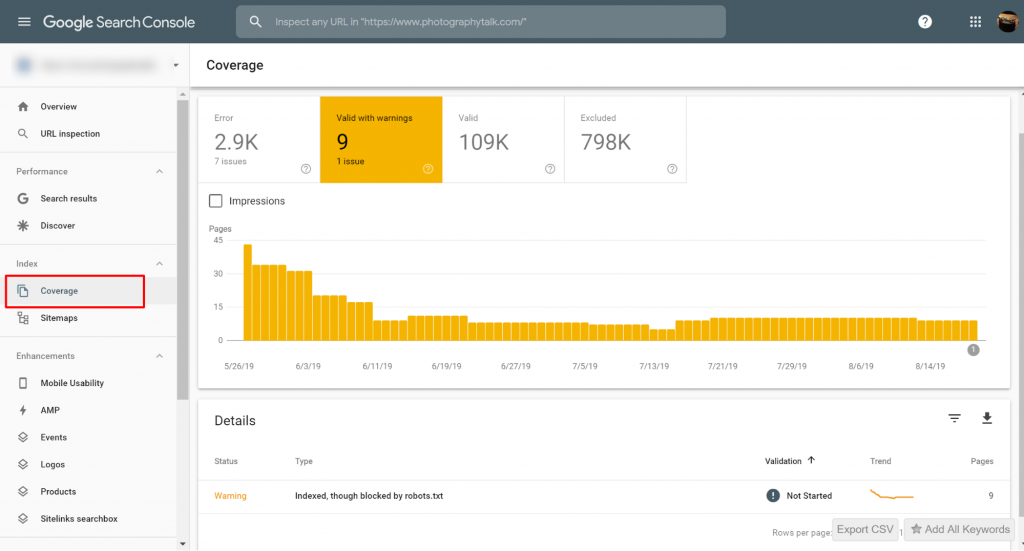
Du kan se sider med de [Indekserede], men blokeret af robots.txt problemer på Google Search Console>>Dækning. Hvis du ikke ser advarselsmærket, så er du fri og klar.
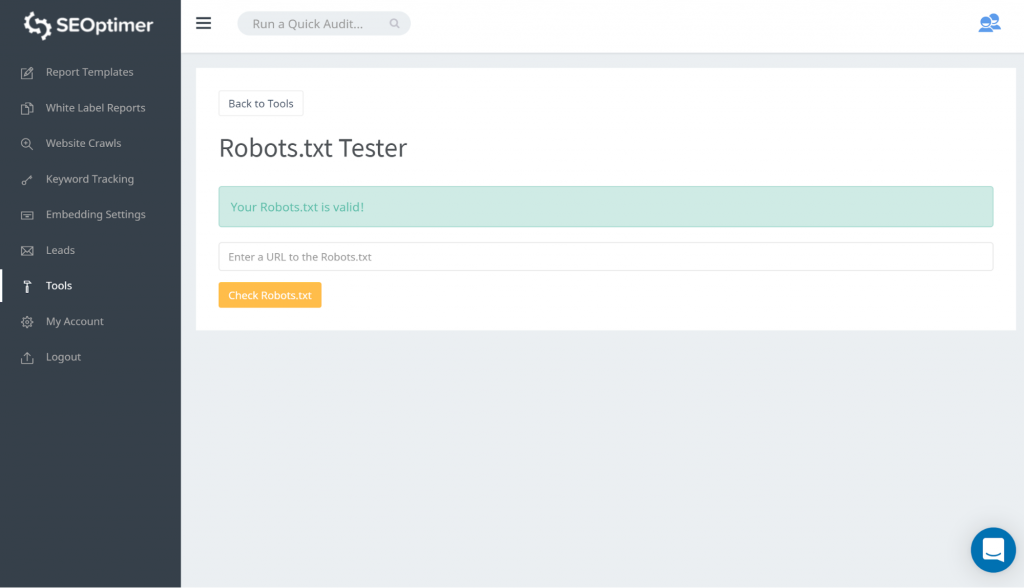
En måde at teste din robots.txt er ved at bruge vores robots.txt tester. Du kan finde ud af, at du er okay med, at hvad end der bliver blokeret forbliver ‘blokeret’. Du behøver derfor ikke at tage nogen handling.
Du kan også følge dette GSC link. Du skal derefter:
- Åbn listen over de blokerede ressourcer og vælg domænet.
- Klik på hver ressource. Du bør se denne popup:
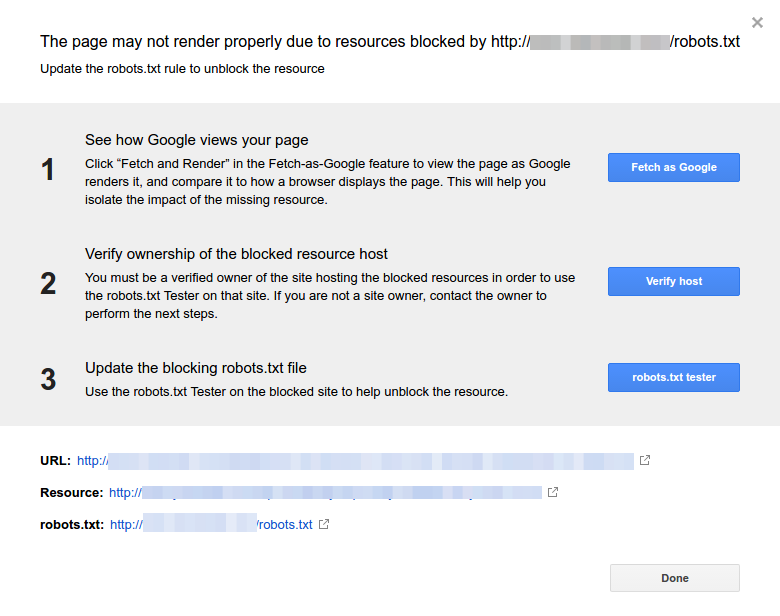
Identificer årsagen til meddelelsen
Meddelelsen kan skyldes flere årsager. Her er de almindelige:
Men først, det er ikke nødvendigvis et problem, hvis der er sider, der er blokeret af robots.txt. Det kan være designet af årsager, såsom at udvikleren ønsker at blokere unødvendige / kategorisider eller dubletter. Så, hvad er uoverensstemmelserne?
Forkert URL-format
Nogle gange kan problemet opstå fra en URL, der ikke rigtig er en side. For eksempel, hvis URL'en https://www.seoptimer.com/da/?s=digital+marketing, skal du vide, hvilken side URL'en løser til.
Hvis det er en side, der indeholder betydeligt indhold, som du virkelig har brug for, at dine brugere ser, så skal du ændre URL'en. Dette er muligt på Content Management Systems (CMS) som Wordpress, hvor du kan redigere en side’s slug.
Hvis siden ikke er vigtig, eller med vores /?s=digital+marketing eksempel, det er en søgeforespørgsel fra vores blog, så er der ingen grund til at rette GSC-fejlen.
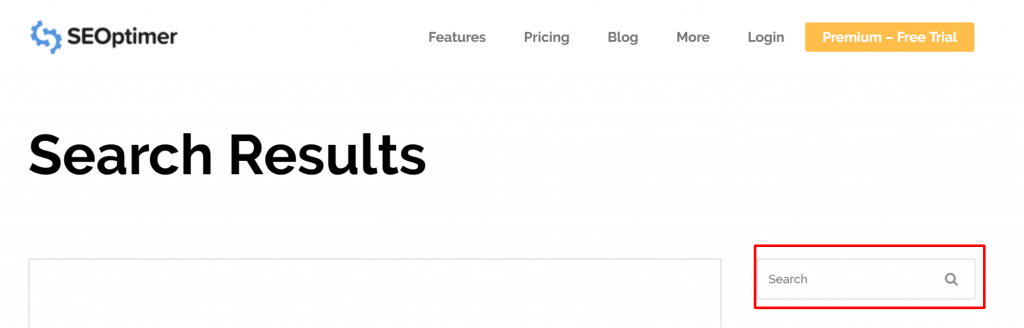
Det gør ingen forskel, om det er indekseret eller ej, da det ikke engang er en rigtig URL, men en søgeforespørgsel. Alternativt kan du slette siden.
Sider, der bør indekseres
Der er flere grunde til, at sider, der burde indekseres, ikke bliver indekseret. Her er nogle få:
- Har du tjekket dine robots-direktiver? Du kan have inkluderet direktiver i din robots.txt-fil, der forhindrer indeksering af sider, der faktisk bør indekseres, for eksempel tags og kategorier. Tags og kategorier er faktiske URL'er på dit site.
- Peger du Googlebot til en omdirigeringskæde? Googlebot går gennem hvert link, de kan støde på, og gør deres bedste for at læse til indeksering. Men hvis du opsætter en flere, lange, dybe omdirigeringer, eller hvis siden bare er utilgængelig, vil Googlebot stoppe med at kigge.
- Implementeret det kanoniske link korrekt? En kanonisk tag bruges i HTML-headeren til at fortælle Googlebot, hvilken side der er den foretrukne og kanoniske side i tilfælde af duplikeret indhold. Hver side bør have en kanonisk tag. For eksempel, hvis du har en side, der er oversat til spansk. Du vil selv kanonisere den spanske URL, og du vil kanonisere siden tilbage til din standard engelske version.
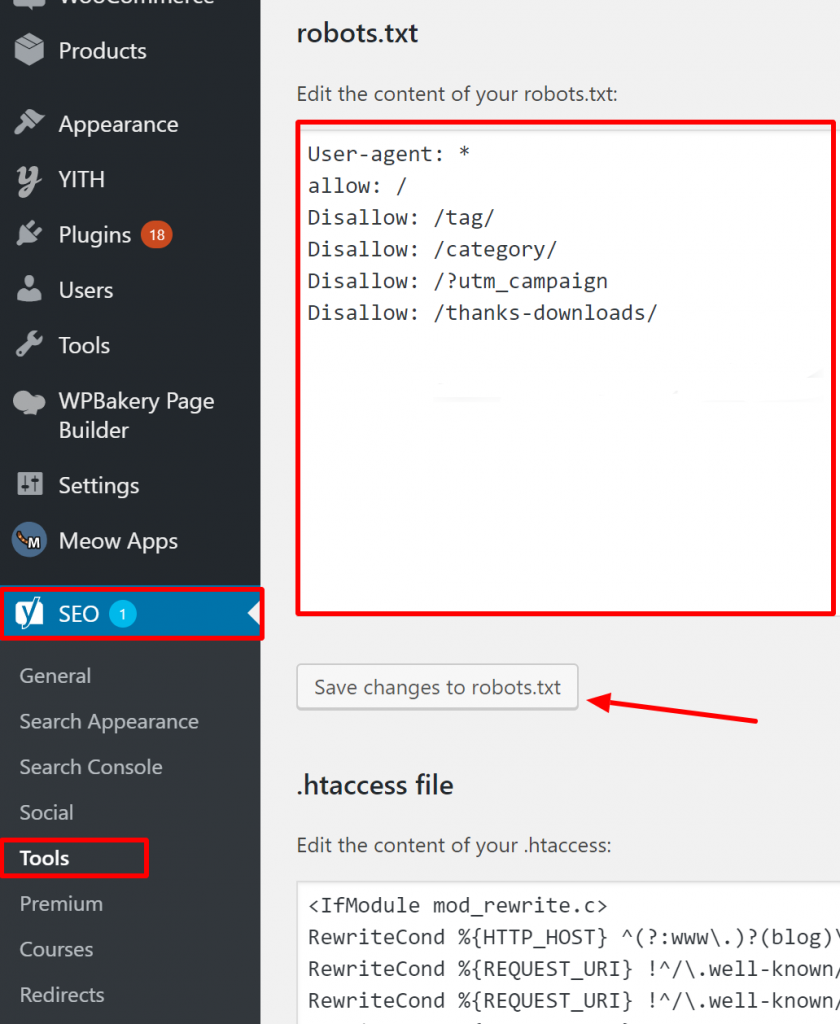
Hvordan verificerer du, at din Robots.txt er korrekt på WordPress?
For WordPress, if your robots.txt file is part of the site install, use the Yoast Plugin to edit it. If the robots.txt file that is causing issues is on another site that is not your own, you need to communicate with the site owners and request them to edit their robots.txt file.
Sider, der ikke bør indekseres
Der er flere grunde til, at sider, der ikke bør indekseres, bliver indekseret. Her er nogle få:
Robots.txt-direktiver, der ‘siger’, at en side ikke skal indekseres. Bemærk, at du skal tillade, at siden med en ‘noindex’-direktiv bliver crawlet, så søgemaskinernes bots ‘ved’, at den ikke skal indekseres.
I din robots.txt-fil, sørg for at:
- Linjen ‘disallow’ følger ikke umiddelbart efter linjen ‘user-agent’.
- Der er ikke mere end én ‘user-agent’ blok.
- Usynlige Unicode-tegn - du skal køre din robots.txt-fil gennem en teksteditor, som vil konvertere kodninger. Dette vil fjerne eventuelle specialtegn.
Sider er linket til fra andre sites. Sider kan blive indekseret, hvis de er linket til fra andre sites, selvom de er forbudt i robots.txt. I dette tilfælde vises kun URL'en og ankerteksten i søgeresultaterne. Sådan vises disse URL'er på søgeresultatsiden (SERP):
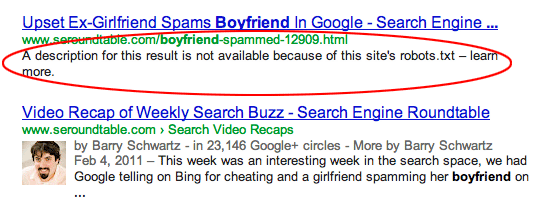
billedkilde Webmasters StackExchange
En måde at løse problemet med blokering af robots.txt er ved at beskytte filen/filene med adgangskode på din server.
Alternativt, slet siderne fra robots.txt eller brug følgende meta tag til at blokere
dem:
<meta name=”robots” content=”noindex”>
Gamle URL'er
Hvis du har oprettet nyt indhold eller en ny side og brugt en ‘noindex’ direktiv i robots.txt for at sikre, at det ikke bliver indekseret, eller for nylig tilmeldt dig GSC, er der to muligheder for at løse problemet blokeret af robots.txt:
- Giv Google tid til at fjerne de gamle URL'er fra sit indeks
- 301 omdiriger de gamle URL'er til de nuværende
I det første tilfælde fjerner Google til sidst URL'er fra sin indeks, hvis alt de gør er at returnere 404'er (hvilket betyder, at siderne ikke eksisterer). Det er ikke tilrådeligt at bruge plugins til at omdirigere dine 404'er. Plugins kan forårsage problemer, der kan føre til, at GSC sender dig advarslen ‘blokeret af robots.txt’.
Virtuelle robots.txt-filer
Der er en mulighed for at få notifikation, selvom du ikke har en robots.txt-fil. Dette skyldes, at CMS (Customer Management Systems) baserede sider, for eksempel, WordPress har virtuelle robots.txt-filer. Plug-ins kan også indeholde robots.txt-filer. Disse kunne være dem, der forårsager problemer på din side.
Disse virtuelle robots.txt skal overskrives af din egen robots.txt-fil. Sørg for, at din robots.txt inkluderer en direktiv, der tillader alle søgemaskinebots at crawle dit site. Dette er den eneste måde, de kan fortælle, hvilke URL'er der skal indekseres eller ej.
Her er direktivet, der tillader alle bots at crawle din side:
User-agent: *
Forbyd: /
Det betyder ‘ikke tillade noget’.
Afslutningsvis
Vi har kigget på ‘Indekseret, men blokeret af robots.txt-advarsel’, hvad det betyder, hvordan man identificerer de berørte sider eller URL'er, samt årsagen bag advarslen. Vi har også kigget på, hvordan man løser det. Bemærk, at advarslen ikke er lig med en fejl på dit site. Men hvis man undlader at løse det, kan det resultere i, at dine vigtigste sider ikke bliver indekseret, hvilket ikke er godt for brugeroplevelsen.