ウェブをナビゲートする際、ユーザーと検索エンジンの両方がアクセスの問題を示すさまざまなHTTPエラーコードに遭遇することがあります。これらの中で、401 "Unauthorized" と403 "Forbidden" エラーコードは最も一般的なものの2つです。
これらのHTTP応答ステータスコードは、リクエストが「成功した」か「失敗した」かを示すためにサーバーによって送信されます。
しかし、401エラーコードと403エラーコードの本当の違いは何でしょうか?このブログ記事では、それを分解して、これらのエラーがあなたのSEOにどのように影響を与えるかを説明します。
401と403エラーコードの違いは何ですか?
エラーコード401と403の両方が、サーバー上のリソースへのアクセスに関する問題を示しています。
こちらが401と403のサーバーレスポンスの主な違いです:
認証
401エラーは、サーバーへの不正アクセス試行があった場合に発生します。
対照的に、403 Forbidden エラーは、サーバーがユーザーを認識しているが、必要な権限がないと判断した場合に発生します。
言い換えれば、403ステータスコードは、ユーザーが有効な資格情報を提供したが、それでもコンテンツを表示するための適切な権限が不足していることを意味します。
解決方法
401ステータスコードの場合、問題はユーザーが正しいユーザー名やパスワードなどの有効な資格情報を提供することで解決されます。
対照的に、403ステータスコードは、ユーザーがすでに正確な資格情報を提供しているため、異なるアプローチが必要です。問題を解決するには、ユーザーの「権限」を確認して調整するか、リソースへのアクセスを妨げているサーバーによる「制限」を解決することができます。
複雑さ
HTTP 401 Unauthorized エラーは、基本認証やベアラートークン認証のような認証プロトコルを満たすことができないことを中心にしているため、より複雑ではありません。
あるいは、HTTP 403 Forbidden エラーはより技術的に複雑です。アクセス制御リスト、ロールベースのアクセス制御、または任意アクセス制御を評価する必要があります。
ここでは、サーバーがポリシーに基づく制限を強制し、適切な認証ヘッダーが提供されていても、[不十分な]権限に基づいてアクセスを拒否します。
401エラーコードとは何ですか?
HTTP 401ステータスコードは、クライアントのリクエストが「認証されていない」ことを示します。サーバーは、有効な「資格情報」がないため、クライアントの「身元」を確認できません。
401エラーは次の理由で発生します:
- 資格情報が提供されていません: [もし]ユーザーがファイルにアクセスしようとしたが、認証資格情報が欠落している[場合]。時々、ユーザーは適切に署名されたトークンを提供できず、それがアクセス拒否につながることがあります。
- 無効な資格情報: ログイン失敗の問題は、サーバーの誤った構成やデータベース接続の誤りによっても発生する可能性があります。この場合、ユーザーは資格情報を提供しますが、それが正しくないか、TLS認証が適切に構成されていません。
- 期限切れの資格情報: 多くの場合、キャッシュされた資格情報が期限切れとなり、再認証が必要になります。いくつかの誤った設定により、ログインページが読み込み続ける無限ループに陥ることもあります。
- 権限が不十分: ユーザーは認証されていますが、目的のファイルに到達するために必要な承認が不足しています。
- 認証ヘッダーが欠落しています: ユーザーがリクエストに必要な認証ヘッダーを含めていません。
- クッキーの問題: セッションまたは認証クッキーが存在しない、古い、または不正確な場合、サーバーは401ステータスコードを発行します。これにより、ユーザーは再度ログインする必要があります。
サーバーの応答には、必要な認証方法(例: "Basic"、"Digest"、"Bearer")を指定するWWW-Authenticateヘッダーが含まれています。このヘッダーは、クライアントに必要な資格情報の提供を促します。
資格情報が無効な場合、有効な資格情報が提供されるまでサーバーは401ステータスを返します。
403エラーコードとは何ですか?
403ステータスコードは、サーバーがクライアントのリクエストを理解しているが、それに対する許可を与えることを拒否していることを示しています。ユーザーの認証情報が有効である可能性があるにもかかわらず、サーバーはリソースへのアクセスを許可することを拒否します。
HTTP 403エラーは、次の理由で返されます:
権限が不十分です
ユーザーは提供された資格情報で正常に認証されました。しかし、ユーザーは目的のファイルやURLを「読み取る」ことも、「書き込む」ことも、「実行する」こともできません。
IPアドレスがブロックされました
ユーザーのIPアドレスが以前のユーザーから悪い履歴を引き継いでいる場合、サーバーはそのIPアドレスをブロックする可能性があります。
あまりにも多くの[不正な]ログイン試行が原因で発生する可能性もあります。
理由が何であれ、IPアドレスがブロックされると、サーバーはHTTP 403応答コードを返します。
リクエストは"セキュリティ設定"によってブロックされました
リクエストは、[セキュリティ]設定([ファイアウォール]ルールなど)によってブロックされています。
地理的制限
ユーザーは、誤ったCDNの誤設定により、[自分の]場所に基づいてコンテンツにアクセスできません。これは、ファイアウォールルール、IPブロッキング、または地域特有のライセンス契約によっても発生する可能性があります。
アクセス制御リスト (ACL) 制限
サーバーは、許可リストに基づいてアクセスをブロックします。これらのリストは、どの個人またはグループがリソースの使用を許可されているか、または禁止されているかを決定します。
無効または欠落しているSSL/TLS証明書
アクセスが制限されています。ユーザーが有効なSSL/TLS証明書なしでサーバーに接続しようとしているためです。
リソースは明示的に禁止されています
サーバーは要求されたリソースへのアクセスを明示的に禁止するように構成されています。
ブロックされたユーザーエージェント
リクエストは拒否されました。なぜなら、サーバーがユーザーのブラウザまたはボットをブロックしているからです。
ディレクトリの一覧表示が拒否されました
サーバーはディレクトリリストを防ぐように設定されています。ユーザーはインデックスファイルがないディレクトリにアクセスしようとします。
ファイルまたはディレクトリの権限
サーバーはアクセスを制限するように権限が設定されており、ユーザーがリソースに到達するのを妨げています。
リファラーポリシーの制限
リクエストは、許可されていないリファラーURLから発信されているため、ブロックされています。
レート制限またはクォータ
ユーザーがサーバーによって課せられたアクセスの割り当てまたはレート制限を超えたため、さらなるリクエストが拒否されました。
認証が必要ですが提供されていません
リソースへのアクセスは制限されています。なぜなら、サーバーは認証を期待しているのに、ユーザーがそれを提供しなかったからです。
サーバーの403エラーへの応答には、認証が問題ではないため、WWW-Authenticateヘッダーが含まれていません。代わりに、サーバーがリクエストを理解しているが、明示的にアクセスを拒否していることを示しています。
403ステータスが返された場合、異なる資格情報を提供しても問題は解決しません。クライアントはリソースにアクセスするための適切な権限を取得する必要があります。
[禁止]と[許可されていない]の違いは何ですか?
両方の用語「Forbidden」と「Unauthorized」は、HTTPレスポンスにおける異なる種類のアクセス問題を表しています。
ForbiddenとUnauthorizedの違いを見つけてみましょう。
401 はクライアント側のエラーで、リクエストに有効な認証資格情報が欠けており、ユーザーがサーバーにアクセスする「権限がない」ことを示しています。そのため、エラーページが読み込まれます。
これを解決するには、クライアントがサーバーの応答にあるWWW-Authenticateヘッダーで示されているように、有効な認証情報を提供する必要があります。
逆に、403エラーは、サーバーがリクエストを理解しているが、資格情報が正しい場合でもアクセスを許可しないことを示しています。したがって、この場合、リソースへのアクセスは「[禁止]」されたままです。
これは、クライアントが認証されているが、必要な権限と特権を持っていない場合に発生します。クライアントは適切な権限なしにリソースを取得することはできず、異なる資格情報を使用しても問題は解決しません。
401および403エラーコードはSEOにどのように影響するか
401および403エラーコードは、いくつかの方法でSEOに悪影響を与える可能性があります:
イライラするユーザー体験
401または403のレスポンスコードに遭遇することは、ユーザーにとって「イライラ」することがあります。これらのHTTPエラーは、ユーザーが閲覧する「許可」を持っていると信じているコンテンツにアクセスしようとしたときに「よく」発生します。
この予期しない障害は、混乱と不満を引き起こし、サイトとのやり取りの流れを中断させる可能性があります。
その結果は単なる即時の混乱ではなく、これらのエラーはユーザーがよりアクセスしやすい代替を求めてサイトをすぐに退出する可能性があるため、直帰率を大幅に増加させる可能性があります。
時間が経つにつれて、これはセッションの持続時間、ページ訪問、コンバージョン率を含む主要なユーザーインタラクション指標に悪影響を及ぼし、最終的には全体的なユーザーエクスペリエンスとサイトの目標達成における効果を損なう可能性があります。
内部リンクとサイト構造の「混乱」
ページへの内部リンクが401 Unauthorizedまたは403 Forbiddenエラーを返す場合、リンクエクイティは渡されません。
それは適切なサイトアーキテクチャの作成を妨げ、「訪問者の体験」を損なうことになります。
ドメインにあまりにも多くのURLがあり、これらのHTTPエラーコードを廃止することは、ウェブサイトの全体的なSEOスコアに悪影響を与えます。
リンクの権威が弱まると、あなたのサイトのオーガニックランキングが低下します。これにより、オーガニックトラフィックが減少し、[コンバージョン]が減少します。
したがって、サーバーが401を返すか403を返すかは関係ありません。どちらもサイトのSEOにとって「有害」です。
インデックス作成と検索可視性の低下
検索エンジンは、「無効な資格情報」または「アクセス禁止」の問題を返すページをインデックスしません。
したがって、検索結果に表示されません。これにより、サイトの可視性が制限され、オーガニック検索トラフィックが減少する可能性があります。
さらに、重要または価値のあるコンテンツへのアクセスをブロックすることは、関連する検索クエリでサイトがうまくランク付けされる能力を妨げる可能性があります。
401エラーコードと403エラーコードの間に類似点はありますか?
はい、401コードと403コードの主な類似点は次のとおりです:
アクセス拒否
401と403の両方のエラーコードは、リソースへのアクセスが拒否されていることを示しています。これは、サーバーがクライアントに要求されたコンテンツを提供することを拒否していることを意味します。どちらの場合も、クライアントは意図した通りにリソースを表示または操作することができません。
これら2つのエラーコードはHTTPプロトコルの一部であり、特定のアクセス問題を示すためにウェブサーバーとクライアントによって広く認識されています。
検索エンジンのクロールへの影響
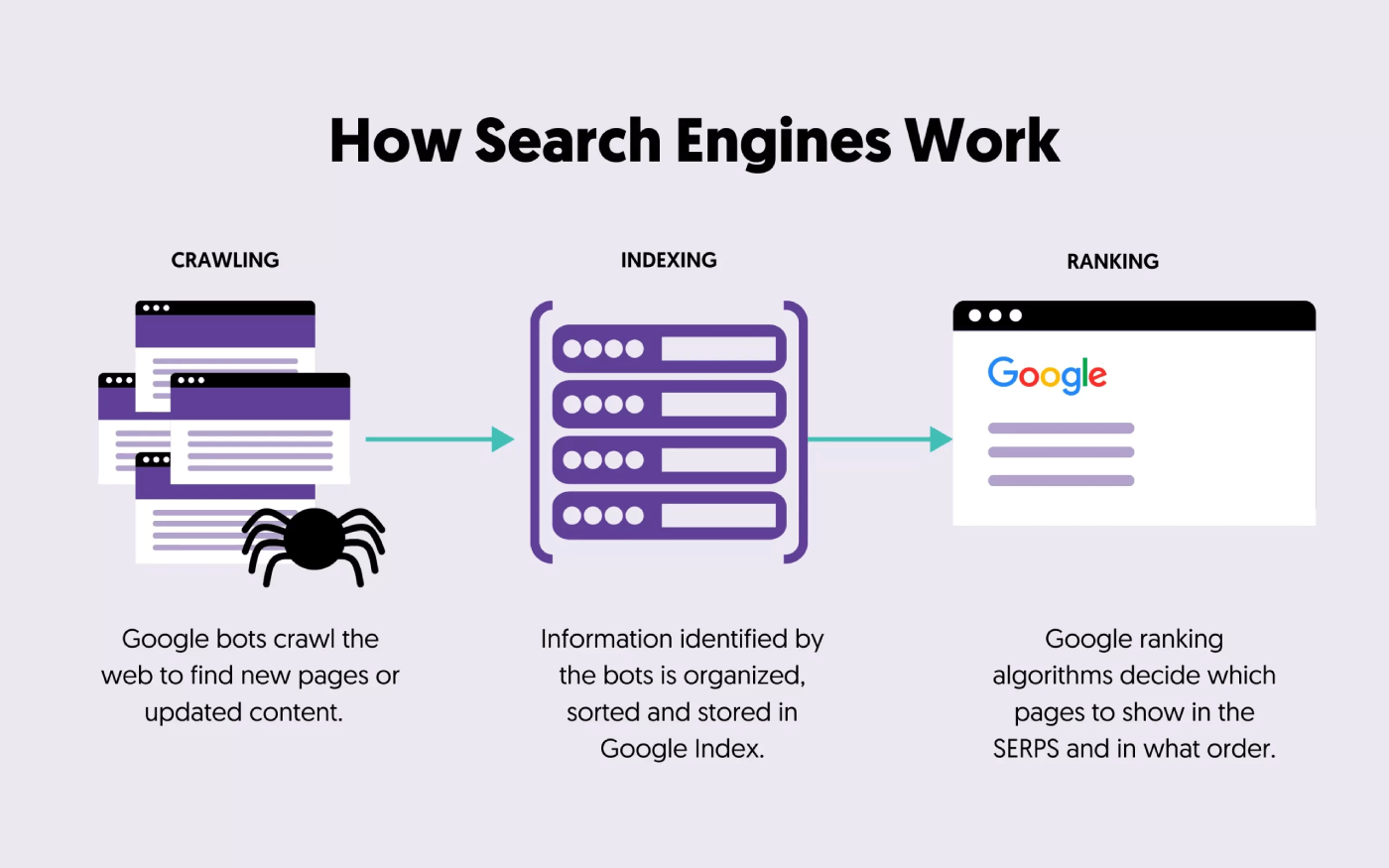
HTTP 401エラーと403エラーの両方が、Googlebotや他のウェブクローラーが影響を受けたページにアクセスしてインデックスすることを防ぎます。
検索エンジンがこれらのエラーに遭遇すると、影響を受けたページをそのインデックスに含めません。したがって、[自然検索]トラフィックの減少につながります。
応答の動作
401 Unauthorized と 403 Forbidden エラーの両方は、クライアントからのさらなるアクションが必要であることを示しています。しかし、そのアクションの性質は異なります。
401エラーの場合、有効な認証資格情報を提供する必要があります。403エラーの場合、適切な権限またはアクセス権を取得する必要があります。
エラー処理とユーザーエクスペリエンス
401エラーと403エラーの両方がユーザーのフラストレーションにつながります。サイト訪問者はコンテンツにアクセスできないことを示すメッセージを目にし、これがユーザーの満足度に影響を与え、直帰率を増加させる可能性があります。
どちらのエラーも、ユーザーが望むコンテンツや機能にアクセスできない場合、[poor]なユーザー体験につながる可能性があります。
セキュリティ
どちらのステータスコードも、ウェブリソースを保護するために不可欠です。これにより、検証済みアカウントのみが機密データにアクセスできるようにします。
これは情報の真正性とプライバシーを維持するのに役立ちます。アクセスを制限することにより、これらのコードは不正なユーザーがプライベートなコンテンツを閲覧または変更するのを防ぎます。
彼らはまた、潜在的なセキュリティ侵害に対する「追加の防御層」を提供します。
401と403エラーコードを識別する方法は?
401および403エラーコードを識別する方法はいくつかあります:
Google Search Consoleを使用する
Google Search Consoleは、401および403の問題を特定するのに役立ちます。
Google Search Consoleにログインし、"[インデックス] "セクションに移動します。
次に、“ページ”をクリックして、以下に関連するエラーを見つけてください:
- 「不正なリクエスト」によりブロックされました (401) または
- 「アクセス禁止」によりブロックされました (403)
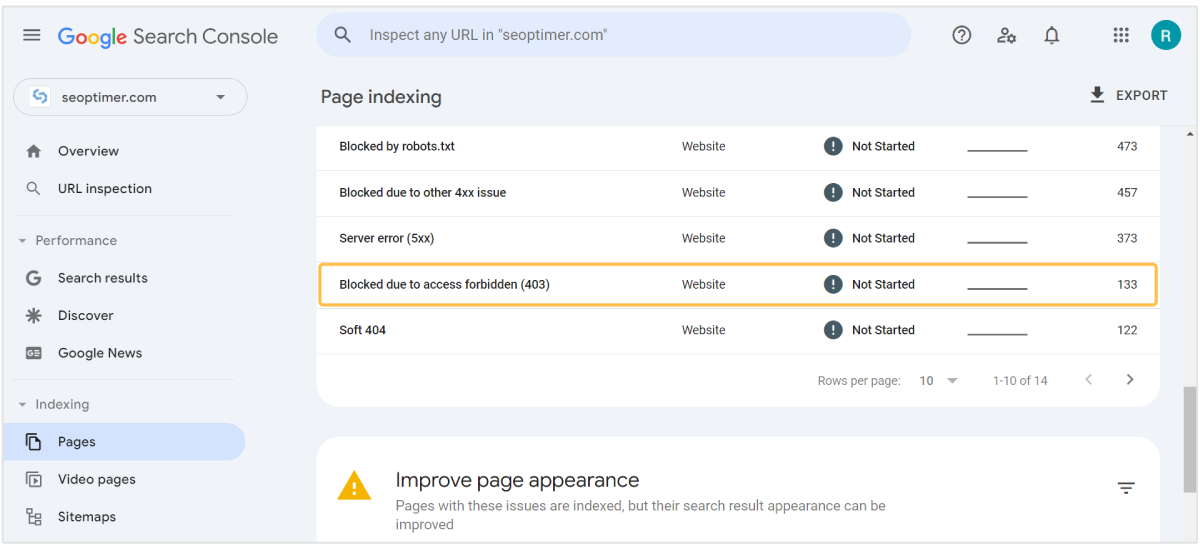
理由(エラー)名をクリックすると、この問題を抱えているURLの完全なリストが表示されます。このリストをエクスポートして、適切な対策を講じることができます。
SEOptimer URLステータスコードチェッカーの「助けを借りる」
SEOptimerのURL Status Code Checkerを使用して、ページのステータスコードを評価することもできます。
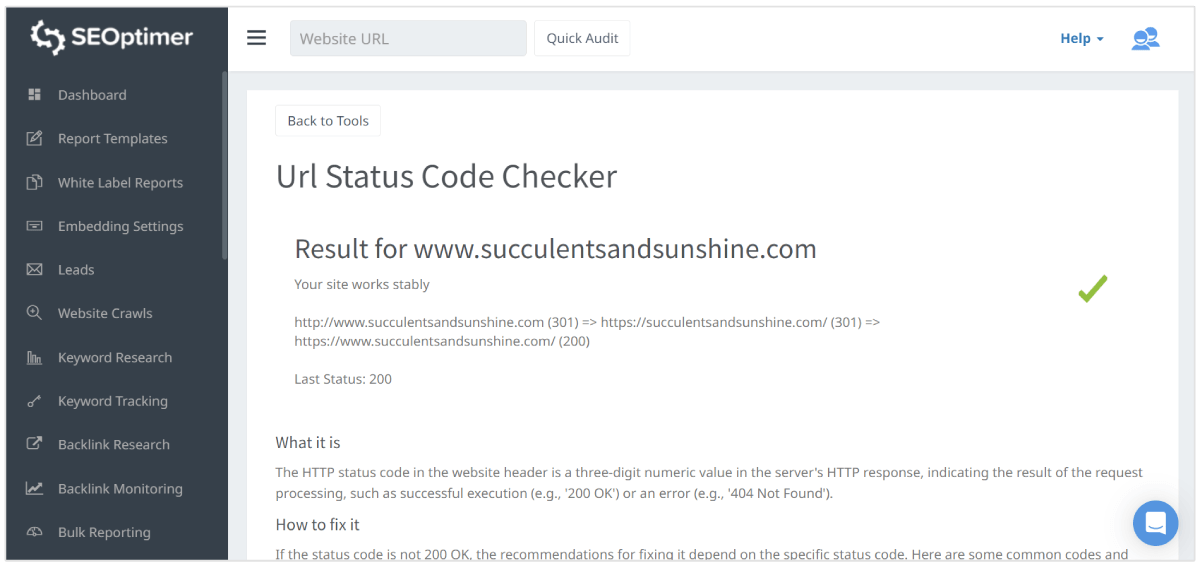
ツールはステータスコードが200であるかどうかを確認します。そうでない場合、応答が[拒否] (403) または[許可されていない] (401) であるかどうかも判断します。
WWW-Authenticate ヘッダーを検査する
ブラウザで開発者ツールを開くには、ページを右クリックして「[検証]」を選択するか、F12キーを押します。
ページを更新してすべてのHTTPリクエストをキャプチャするために、"Network"タブに移動します。
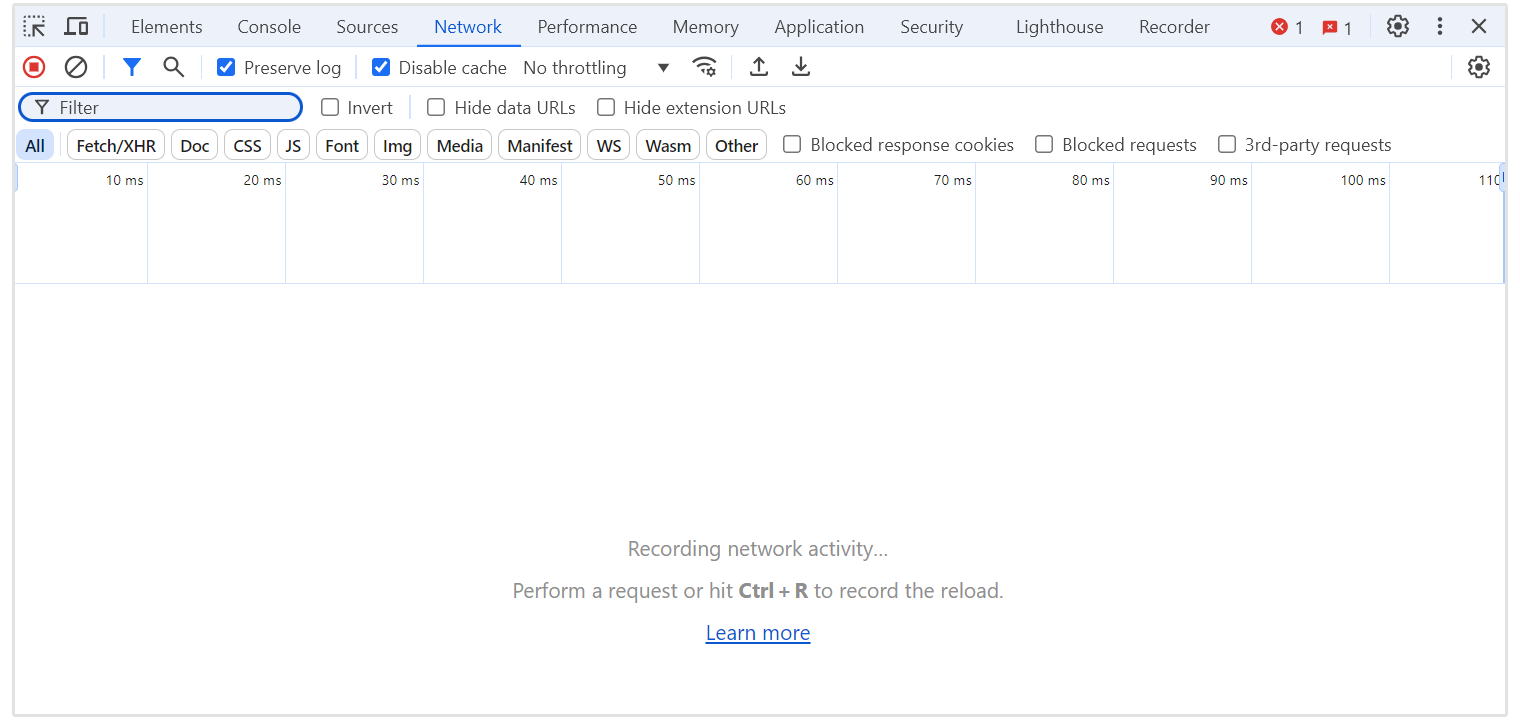
401または403ステータスコードをもたらしたリクエストを探し、それをクリックして詳細を表示します。
"ヘッダー" タブで、"レスポンスヘッダー" セクションをスクロールして、WWW-Authenticate ヘッダーを見つけてください。
このヘッダーは、サーバーが要求する認証方法の詳細を提供し、アクセスが拒否された理由とエラーを解決するために必要な手順を理解するのに役立ちます。
結論
覚えておいてください、401エラーと403エラーは異なることを伝えています。
401 Unauthorizedの応答は、詳細が無効であるため、サーバーがユーザーを認識できないことを示しています。
403 Forbidden エラー応答ステータスコードは、サーバーがリクエストを理解したことを示しています。しかし、[insufficient]な[permission]のために処理に失敗しました。
ユーザー権限が更新されない限り、エラーは戻り続けるので、再ログインする意味はありません。
401ステータスコードと403ステータスコードの違いを理解することは、アクセスの問題を解決し、サイトをすべての人にとってスムーズに運営するのを容易にします。