Wat is Robots.txt?
Robots.txt is een bestand in tekstvorm dat bot crawlers instrueert om bepaalde pagina's wel of niet te indexeren. Het wordt ook wel de poortwachter van je hele site genoemd. Het eerste doel van bot crawlers is om het robots.txt-bestand te vinden en te lezen, voordat ze toegang krijgen tot je sitemap of andere pagina's of mappen.
Met robots.txt kun je meer specifiek:
- Reguleer hoe zoekmachinebots je site crawlen
- Bied bepaalde toegang
- Help zoekmachinespiders de inhoud van de pagina te indexeren
- Toon hoe inhoud aan gebruikers moet worden geserveerd
Robots.txt is een onderdeel van het Robots Exclusion Protocol (R.E.P), bestaande uit de site/pagina/URL niveau richtlijnen. Terwijl zoekmachine bots nog steeds je hele site kunnen crawlen, is het aan jou om hen te helpen beslissen of bepaalde pagina's de tijd en moeite waard zijn.
Waarom je Robots.txt nodig hebt
Uw site heeft geen robots.txt-bestand nodig om correct te functioneren. De belangrijkste redenen waarom u een robots.txt-bestand nodig heeft, is zodat wanneer bots uw pagina crawlen, ze om toestemming vragen om te crawlen, zodat ze kunnen proberen informatie over de pagina op te halen om te indexeren. Bovendien vraagt een website zonder een robots.txt-bestand in feite aan botcrawlers om de site naar eigen inzicht te indexeren. Het is belangrijk te begrijpen dat bots uw site nog steeds zullen crawlen zonder het robots.txt-bestand.
De locatie van je robots.txt-bestand is ook belangrijk omdat alle bots zullen zoeken naar www.123.com/robots.txt. Als ze daar niets vinden, gaan ze ervan uit dat de site geen robots.txt-bestand heeft en indexeren ze alles. Het bestand moet een ASCII- of UTF-8-tekstbestand zijn. Het is ook belangrijk op te merken dat regels hoofdlettergevoelig zijn.
Hier zijn enkele dingen die robots.txt wel en niet zal doen:
- Het bestand kan de toegang van crawlers tot bepaalde delen van je website regelen. Je moet heel voorzichtig zijn bij het instellen van robots.txt, omdat het mogelijk is om de hele website te blokkeren voor indexering.
- Het voorkomt dat dubbele inhoud wordt geïndexeerd en in zoekmachineresultaten verschijnt.
- Het bestand specificeert de crawlvertraging om te voorkomen dat servers overbelast raken wanneer de crawlers meerdere stukken inhoud tegelijk laden.
Hier zijn enkele Googlebots die van tijd tot tijd op uw site kunnen crawlen:
| Webcrawler | Gebruikersagentreeks |
| Googlebot Nieuws | Googlebot-Nieuws |
| Googlebot Afbeeldingen | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (uitgelichte telefoon) | SAMSUNG-SGH-E250/1.0 Profiel/MIDP-2.0 Configuratie/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatibel; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, zoals Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatibel; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (compatibel; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (PPC bestemmingspagina kwaliteit) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app-crawler (hulpbronnen ophalen voor mobiel) | AdsBot-Google-Mobile-Apps |
Je kunt een lijst van aanvullende bots hier vinden.
- De bestanden helpen bij de specificatie van de locatie van de sitemaps.
- Het voorkomt ook dat zoekmachinebots verschillende bestanden op de website indexeren, zoals afbeeldingen en PDF's.
Wanneer een bot je website wil bezoeken (bijvoorbeeld, www.123.com), controleert het eerst www.123.com/robots.txt en vindt:
Gebruikersagent: *
Disallow: /
Dit voorbeeld instrueert alle (User-agents*) zoekmachinebots om de website niet te indexeren (Disallow: /).
Als je de schuine streep uit Disallow verwijdert, zoals in het onderstaande voorbeeld,
User-agent: *
Niet toestaan:
de bots zouden alles op de website kunnen crawlen en indexeren. Dit is waarom het belangrijk is om de syntax van robots.txt te begrijpen.
De syntax van robots.txt begrijpen
Robots.txt syntax kan worden gezien als de “taal” van robots.txt-bestanden. Er zijn 5 veelvoorkomende termen die je waarschijnlijk tegenkomt in een robots.txt-bestand. Deze zijn:
- User-agent: De specifieke webcrawler waaraan je crawl-instructies geeft (meestal een zoekmachine). Een lijst van de meeste user agents is te vinden hier.
- Niet toestaan: Het commando dat wordt gebruikt om een gebruikersagent te vertellen een bepaalde URL niet te crawlen. Slechts één "Niet toestaan:" regel is toegestaan voor elke URL.
- Toestaan (Alleen van toepassing op Googlebot): Het commando vertelt Googlebot dat het een pagina of submap kan openen, zelfs als de bovenliggende pagina of submap niet is toegestaan.
- Crawl-delay: Het aantal milliseconden dat een crawler moet wachten voordat de pagina-inhoud wordt geladen en gecrawld. Merk op dat Googlebot dit commando niet erkent, maar crawl rate kan worden ingesteld in Google Search Console.
- Sitemap: Gebruikt om de locatie van een XML-sitemap(s) geassocieerd met een URL aan te geven. Let op dat dit commando alleen wordt ondersteund door Google, Ask, Bing en Yahoo.
Robots.txt instructie-uitkomsten
Je verwacht drie uitkomsten wanneer je robots.txt-instructies geeft:
- Volledig toestaan
- Volledig weigeren
- Voorwaardelijk toestaan
Laten we elk hieronder onderzoeken.
Volledig toestaan
Dit resultaat betekent dat alle inhoud op uw website kan worden gecrawld. Robots.txt-bestanden zijn bedoeld om crawling door zoekmachinebots te blokkeren, dus dit commando kan erg belangrijk zijn.
Dit resultaat kan betekenen dat je helemaal geen robots.txt-bestand op je website hebt. Zelfs als je het niet hebt, zullen zoekmachinebots er nog steeds naar zoeken op je site. Als ze het niet vinden, zullen ze alle delen van je website crawlen.
De andere optie onder deze uitkomst is om een robots.txt-bestand te maken maar het leeg te laten. Wanneer de spider komt om te crawlen, zal het de robots.txt-bestand identificeren en zelfs lezen. Aangezien het daar niets zal vinden, zal het doorgaan met het crawlen van de rest van de site.
Als je een robots.txt-bestand hebt en de volgende twee regels erin hebt staan,
User-agent:*
Niet toestaan:
de zoekmachine-spider zal je website crawlen, het robots.txt-bestand identificeren en het lezen. Het zal bij regel twee komen en vervolgens doorgaan met het crawlen van de rest van de site.
Volledig verbieden
Hier zal geen inhoud worden gecrawld en geïndexeerd. Dit commando wordt uitgegeven door deze regel:
User-agent:*
Disallow:/
Wanneer we het hebben over geen inhoud, bedoelen we dat niets van de website (inhoud, pagina's, enz.) kan worden gecrawld. Dit is nooit een goed idee.
Voorwaardelijk Toestaan
Dit betekent dat alleen bepaalde inhoud op de website kan worden gecrawld.
Een voorwaardelijke toestemming heeft dit formaat:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Toestaan:/
Je kunt de volledige robots.txt-syntaxis hier vinden.
Let op dat geblokkeerde pagina's nog steeds geïndexeerd kunnen worden, zelfs als je de URL hebt verboden zoals weergegeven in de afbeelding hieronder:
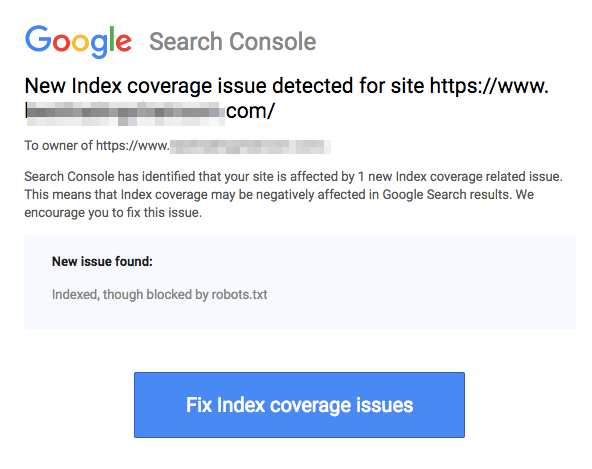
Je kunt een e-mail ontvangen van zoekmachines dat je URL is geïndexeerd zoals in de screenshot hierboven. Als je niet-toegestane URL is gelinkt vanaf andere sites, zoals ankertekst in links, zal het worden geïndexeerd. De oplossing hiervoor is om 1) je bestanden op je server met een wachtwoord te beveiligen, 2) de noindex meta tag te gebruiken, of 3) de pagina volledig te verwijderen.
Kan een robot nog steeds door mijn robots.txt-bestand scannen en negeren?
Ja. het is mogelijk dat een robot robots.txt kan omzeilen. Dit komt omdat Google andere factoren gebruikt zoals externe informatie en inkomende links om te bepalen of een pagina geïndexeerd moet worden of niet. Als je niet wilt dat een pagina helemaal geïndexeerd wordt, moet je de noindex robots meta tag gebruiken. Een andere optie zou zijn om de X-Robots-Tag HTTP header te gebruiken.
Kan ik alleen slechte robots blokkeren?
Het is theoretisch mogelijk om slechte robots te blokkeren, maar het kan in de praktijk moeilijk zijn om dit te doen. Laten we eens kijken naar enkele manieren om dit te doen:
- Je kunt een slechte robot blokkeren door deze uit te sluiten. Je moet echter de naam weten die de specifieke robot scant in het User-Agent veld. Vervolgens moet je een sectie toevoegen in je robots.txt bestand die de slechte robot uitsluit.
- Serverconfiguratie. Dit zou alleen werken als de slechte robot opereert vanaf een enkel IP-adres. Serverconfiguratie of een netwerkfirewall zal de slechte robot blokkeren van toegang tot je webserver.
- Gebruik maken van geavanceerde firewallregelconfiguraties. Deze zullen automatisch de toegang blokkeren tot de verschillende IP-adressen waar kopieën van de slechte robot bestaan. Een goed voorbeeld van bots die op verschillende IP-adressen opereren is in het geval van gekaapte pc's die zelfs deel kunnen uitmaken van een groter Botnet (leer meer over Botnet hier).
Als de slechte robot opereert vanaf een enkel IP-adres, kun je de toegang tot je webserver blokkeren via serverconfiguratie of met een netwerkfirewall.
Als kopieën van de robot op een aantal verschillende IP-adressen werken, wordt het moeilijker om ze te blokkeren. De beste optie in dit geval is om geavanceerde firewallregelconfiguraties te gebruiken die automatisch de toegang blokkeren tot IP-adressen die veel verbindingen maken; helaas kan dit ook de toegang van goede bots beïnvloeden.
Wat zijn enkele van de beste SEO-praktijken bij het gebruik van robots.txt?
Op dit punt vraag je je misschien af hoe je door deze zeer lastige robots.txt-wateren kunt navigeren. Laten we dit in meer detail bekijken:
- Zorg ervoor dat je geen inhoud of secties van je site blokkeert die je wilt laten crawlen.
- Gebruik een blokkeringsmechanisme anders dan robots.txt als je wilt dat linkwaarde wordt doorgegeven van een pagina met robots.txt (wat betekent dat het praktisch geblokkeerd is) naar de linkbestemming.
- Gebruik robots.txt niet om te voorkomen dat gevoelige gegevens zoals privégebruikersinformatie in zoekresultaten verschijnen. Dit kan ertoe leiden dat andere pagina's linken naar pagina's die privégebruikersinformatie bevatten, waardoor de pagina geïndexeerd kan worden. In dit geval is robots.txt omzeild. Andere opties die je hier kunt verkennen zijn wachtwoordbeveiliging of de noindex meta directive.
- Er is geen noodzaak om richtlijnen te specificeren voor elk van de crawlers van een zoekmachine, aangezien de meeste user agents, als ze tot dezelfde zoekmachine behoren, dezelfde regels volgen. Google gebruikt Googlebot voor zoekmachines en Googlebot Image voor zoekopdrachten naar afbeeldingen. Het enige voordeel van weten hoe je elke crawler moet specificeren, is dat je precies kunt afstemmen hoe de inhoud op je site wordt gecrawld.
- Als je het robots.txt-bestand hebt gewijzigd en je wilt dat Google het sneller bijwerkt, dien het dan rechtstreeks in bij Google. Voor instructies over hoe je dat doet, klik hier. Het is belangrijk op te merken dat zoekmachines de inhoud van robots.txt cachen en de gecachte inhoud minstens één keer per dag bijwerken.
Basisrichtlijnen voor robots.txt
Nu je een basisbegrip hebt van SEO in relatie tot robots.txt, welke dingen moet je in gedachten houden bij het gebruik van robots.txt? In deze sectie bekijken we enkele richtlijnen om te volgen bij het gebruik van robots.txt, hoewel het belangrijk is om daadwerkelijk de volledige syntaxis te lezen.
Formaat en locatie
De teksteditor die je kiest om een robots.txt-bestand te maken, moet in staat zijn om standaard ASCII- of UTF-8-tekstbestanden te maken. Het gebruik van een tekstverwerker is geen goed idee, omdat er mogelijk enkele tekens worden toegevoegd die het crawlen kunnen beïnvloeden.
Hoewel bijna elke teksteditor kan worden gebruikt om je robots.txt-bestand te maken, wordt deze tool sterk aanbevolen omdat het testen tegen je site mogelijk maakt.
Hier zijn meer richtlijnen over formaat en locatie:
- Je moet het bestand dat je maakt "robots.txt" noemen omdat het bestand hoofdlettergevoelig is. Er worden geen hoofdletters gebruikt.
- Je kunt slechts één robots.txt-bestand op de hele site hebben.
- Het robots.txt-bestand bevindt zich slechts op één plaats: de root van de websitehost waarop het van toepassing is. Let op dat het niet in een subdirectory geplaatst kan worden. Als je website ishttp://www.123.com/, dan is de locatie van robots.txthttp://www.123.com/robots.txt, niet http://www.123.com/pages/robots.txt. Merk op dat het robots.txt-bestand kan gelden voor subdomeinen (http://website.123.com/robots.txt) en zelfs niet-standaard poorten, zoalshttp://www.123.com: 8181/robots.txt
Zoals eerder vermeld, is robots.txt niet de beste manier om te voorkomen dat gevoelige persoonlijke informatie wordt geïndexeerd. Dit is een geldige zorg, vooral nu met de recent geïmplementeerde GDPR. Gegevensprivacy mag niet in gevaar worden gebracht. Punt.
Hoe zorg je er dan voor dat robots.txt geen gevoelige gegevens in zoekresultaten toont?
Het gebruik van een aparte subdirectory die “niet-lijstbaar” is op het web, zal de verspreiding van gevoelig materiaal voorkomen. Je kunt ervoor zorgen dat het “niet-lijstbaar” is door serverconfiguratie te gebruiken. Sla eenvoudigweg alle bestanden die je niet wilt dat robots.txt bezoekt en indexeert op in deze subdirectory.
Leidt het niet vermelden van pagina's of directories in het robots.txt-bestand tot onbedoelde toegang?
Zoals eerder vermeld, het plaatsen van alle bestanden die je niet geïndexeerd wilt hebben in een aparte subdirectory en deze vervolgens on-lijstbaar maken via serverconfiguraties zou ervoor moeten zorgen dat ze niet in zoekresultaten verschijnen. De enige vermelding die je dan in het robots.txt-bestand doet, is de naam van de directory. De enige manier om toegang te krijgen tot deze bestanden is via een directe link naar een van de bestanden.
Hier is een voorbeeld:
In plaats van
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Gebruik
User-Agent:*
Disallow:/norobots/
Je moet dan een "norobots" directory aanmaken, die foo.html en bar.html bevat. Let op dat je serverconfiguraties duidelijk moeten zijn over het niet genereren van een directorylijst voor de "norobots" directory.
Dit is misschien geen erg veilige aanpak omdat de persoon of bot die uw site aanvalt nog steeds kan zien dat u een “norobots” directory heeft, ook al kunnen ze de bestanden in de directory mogelijk niet bekijken. Echter, iemand zou een link naar die bestanden op hun website kunnen publiceren of, erger nog, de link kan verschijnen in een logbestand dat toegankelijk is voor het publiek (bijv. een webserverlog als referrer). Een servermisconfiguratie is ook mogelijk, wat resulteert in een directorylijst.
Wat betekent dit? Robots.txt kan je niet helpen met het controleren van toegang om de simpele reden dat het daar niet voor bedoeld is. Een goed voorbeeld is een “Verboden toegang bord.” Er zijn mensen die de instructie toch zullen negeren.
Als er bestanden zijn die je alleen door geautoriseerde personen wilt laten openen, zullen serverconfiguraties helpen met authenticatie. Als je een CMS (Content Management System) gebruikt, heb je toegangscontroles op individuele pagina's en resourcecollectie.
Kun je robots.txt optimaliseren voor SEO?
Absoluut. De beste gids voor het optimaliseren van robots.txt is de inhoud van de site. Een snelle herinnering: Robots.txt mag nooit worden gebruikt om pagina's te blokkeren voor het crawlen door zoekmachinebots. Gebruik het alleen om de secties van je website te blokkeren die niet toegankelijk zijn voor het publiek, bijvoorbeeld inlogpagina's zoals wp-admin.
Dit is de disallow-regel voor de inlogpagina van Neil Patel op een van zijn websites:
User-agent:*
Disallow:/wp-admin/
Toestaan:/wp-admin/admin-ajax.php
Je kunt deze disallow-regel gebruiken om te voorkomen dat je login wordt geïndexeerd.
Als er specifieke pagina's zijn die je niet geïndexeerd wilt hebben, gebruik dan hetzelfde commando als hierboven. Een voorbeeld:
User-agent:*
Disallow:/pagina/
Geef de pagina op die je niet geïndexeerd wilt hebben na de schuine streep en sluit af met een andere schuine streep. Bijvoorbeeld:
User-agent:*
Disallow:/pagina/bedankt/
Wat zijn enkele van de pagina's die je mogelijk wilt uitsluiten van indexering?
- Dubbele inhoud die opzettelijk is. Wat betekent dit? Soms creëer je opzettelijk dubbele inhoud om een bepaald doel te bereiken. Een goed voorbeeld is een printervriendelijke versie van een bepaalde webpagina. Je kunt robots.txt gebruiken om de indexering van de printervriendelijke versie van de identieke inhoud te blokkeren.
- Bedankpagina's. De reden dat je deze pagina wilt blokkeren voor indexering is simpel: Het is bedoeld als laatste stap in de verkooptrechter. Tegen de tijd dat je bezoekers op deze pagina aankomen, zouden ze de hele verkooptrechter doorlopen moeten hebben. Als deze pagina wordt geïndexeerd, betekent dit dat je mogelijk leads misloopt, of dat je valse leads ontvangt.
Het commando om zo'n pagina te blokkeren is:
Disallow:/dank-je/
Noindex en NoFollow
Zoals we in dit artikel al hebben gezegd, is het gebruik van robots.txt geen 100% garantie dat je pagina niet geïndexeerd wordt. Laten we kijken naar twee manieren om ervoor te zorgen dat je geblokkeerde pagina inderdaad niet geïndexeerd wordt.
De noindex-richtlijn
Dit werkt in combinatie met het disallow-commando. Gebruik beide in uw richtlijn, zoals in:
Disallow:/dank-je/
De nofollow-richtlijn
Dit werkt om Google-bots specifiek te instrueren de links op een pagina niet te crawlen. Dit is geen onderdeel van het robots.txt-bestand. Om de nofollow-opdracht te gebruiken om te voorkomen dat pagina's worden gecrawld en geïndexeerd, moet je de broncode van de specifieke pagina vinden die je niet geïndexeerd wilt hebben.
Plaats dit tussen de openings- en sluitende head-tags:
<meta name = “robots” content=”nofollow”>
Je kunt zowel “nofollow” als “noindex” tegelijkertijd gebruiken. Gebruik deze regel code:
<meta name = “robots” content=”noindex,nofollow”>
Genereren van robots.txt
Als je het moeilijk vindt om robots.txt te schrijven met alle benodigde formaten en syntaxis die je moet begrijpen en volgen, kun je tools gebruiken die het proces vereenvoudigen. Een goed voorbeeld is onze gratis robots.txt generator.
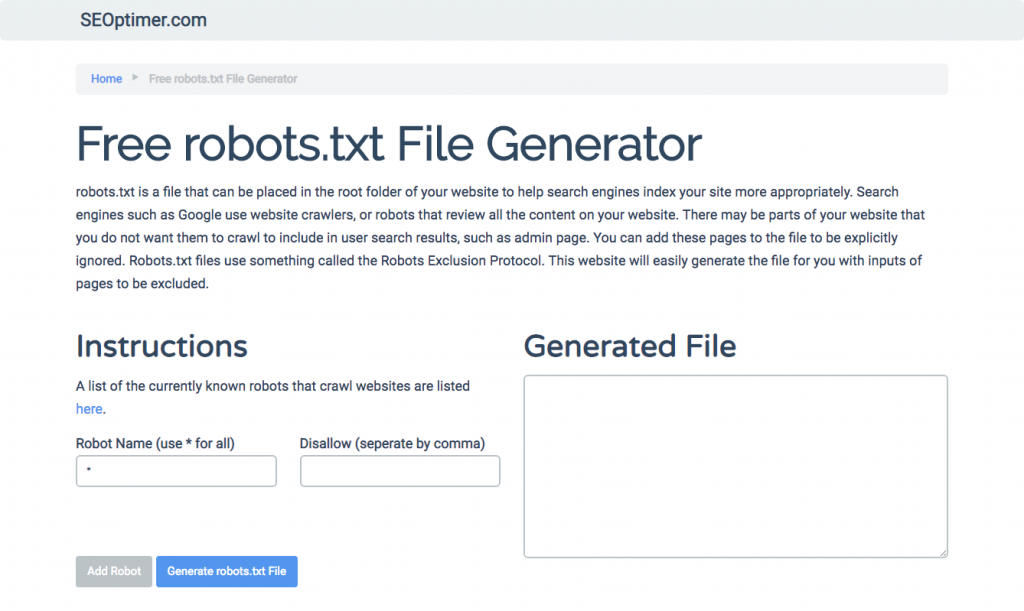
Deze tool stelt je in staat om het type resultaat te kiezen dat je nodig hebt op je website en het bestand of de directories die je wilt toevoegen. Je kunt zelfs je bestand testen en zien hoe je concurrentie het doet.
Uw robots.txt-bestand testen
Je moet je robots.txt-bestand testen om ervoor te zorgen dat het werkt zoals verwacht.
Gebruik de robots.txt-tester van Google.
Om dit te doen, log in op uw Webmaster’s account.
- Selecteer vervolgens uw eigendom. In dit geval is het uw website.
- Klik op “crawlen” in de linkerzijbalk.
- Klik op “robots.txt tester.”
- Vervang eventuele bestaande code door uw nieuwe robots.txt-bestand.
- Klik op “testen.”
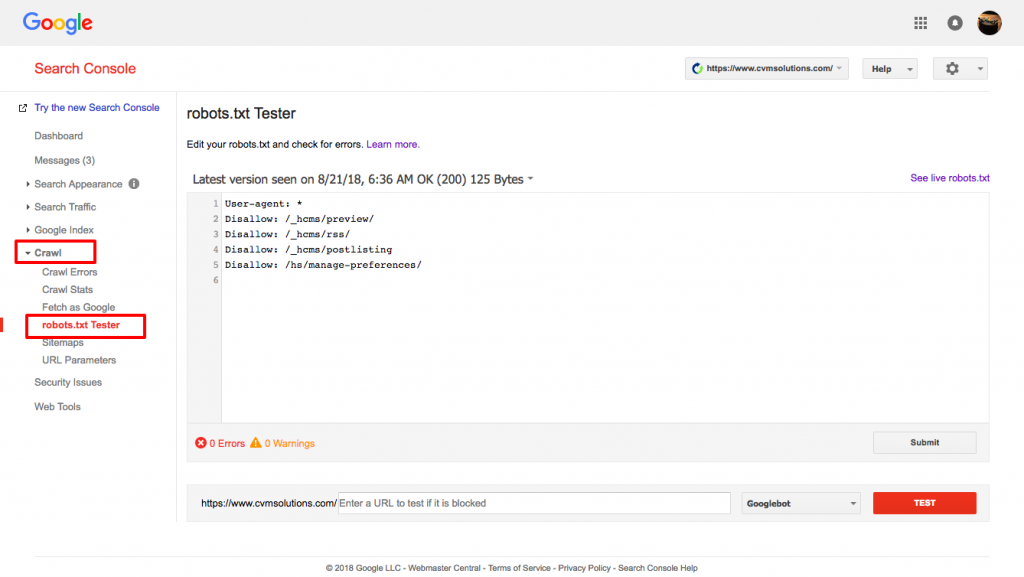
Je zou een tekstvak "toegestaan" moeten kunnen zien als het bestand geldig is. Voor meer informatie, bekijk deze uitgebreide gids voor Google robots.txt tester.
Als uw bestand geldig is, is het nu tijd om het naar uw hoofdmap te uploaden of op te slaan als er al een ander robots.txt-bestand is.
Hoe robots.txt aan je WordPress-site toe te voegen
Om een robots.txt-bestand toe te voegen aan je WordPress-bestand, zullen we de opties voor plugins en FTP behandelen.
Voor de plugin optie, kun je een plug-in gebruiken zoals All in One SEO Pack
Om dit te doen, log in op je WordPress-dashboard
Scroll naar beneden totdat je bij "plugins" komt
Klik op "nieuw toevoegen"
Ga naar "zoek plugins"
Typ “All in One SEO Pack”
Installeer het en activeer
Onder de sectie Algemene Instellingen van de All in One SEO plugin, kun je de noindex en nofollow regels configureren om op te nemen in je robots.txt bestand.
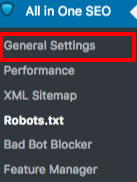
U kunt specificeren welke URL's NOINDEX, NOFOLLOW moeten zijn. Als u deze niet aanvinkt, worden ze standaard geïndexeerd:
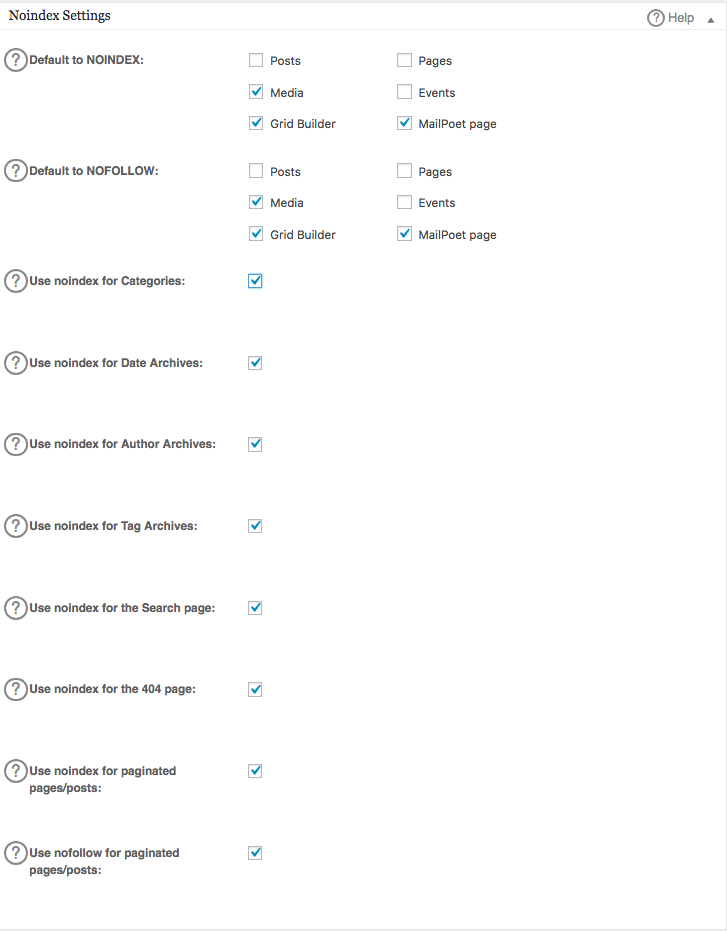
Om geavanceerde regels in uw robots.txt-bestand te maken, klikt u op de functiemanager en vervolgens op de activeren-knop net onder robots.txt.
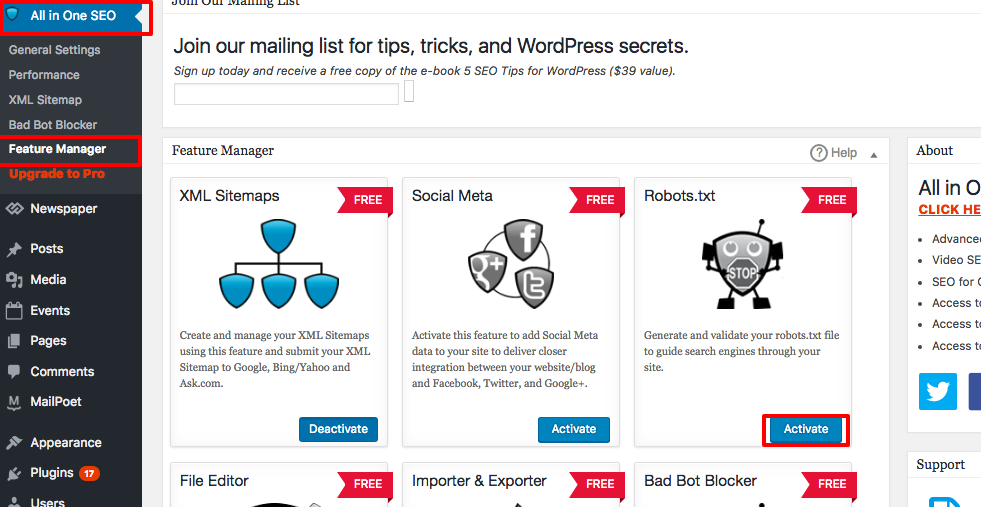
Robots.txt verschijnt nu net onder feature manager. Klik erop. Je ziet een sectie genaamd "create a robots.txt file."
Er is een regelbouwersectie waarmee je de regels kunt kiezen en invullen die je voor je site wilt, afhankelijk van wat je niet geïndexeerd wilt hebben.
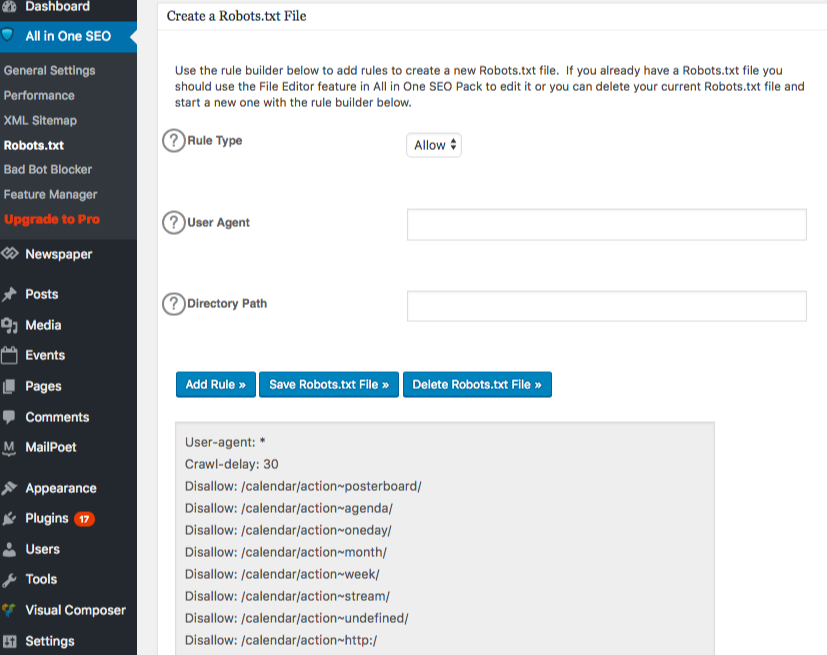
Zodra je klaar bent met het maken van de regel, klik op "regel toevoegen."
De regel wordt dan vermeld onder de robots.txt map die is aangemaakt.
U ziet een bericht dat aangeeft dat "All in One Options" zijn bijgewerkt.
Een andere methode die je kunt gebruiken is om je robots.txt-bestand direct te uploaden naar je FTP (File Transfer Protocol) client zoals FileZilla.
Zodra je je robots.txt-bestand hebt gegenereerd, kun je het lokaliseren en vervangen. Je robots.txt-bestand bevindt zich in: “/applications/[FOLDER NAME]/public_html.”
Hoe het robots.txt-bestand op je Wix te bewerken
Wix genereert een robots.txt-bestand voor websites die gebruikmaken van het webbouwplatform. Om het te bekijken, voeg “/robots.txt” toe aan je domein. De bestanden die aan robots.txt worden toegevoegd, hebben te maken met de structuur van Wix-sites, bijvoorbeeld noflashhtml-links, die niet bijdragen aan de SEO-waarde van je door Wix aangedreven site.
Je kunt je robots.txt-bestand niet bewerken als je site wordt aangedreven door Wix. Je kunt alleen andere opties gebruiken, zoals het toevoegen van een “noindex-tag” aan de pagina's die je niet geïndexeerd wilt hebben.
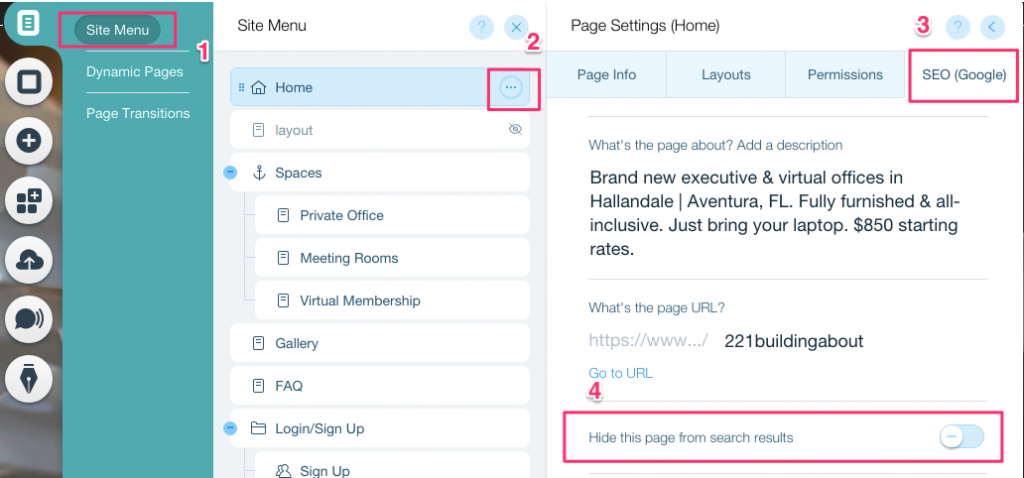
Om een noindex-tag voor een specifieke pagina te maken:
- Klik op Site Menu
- Klik op de optie Instelling voor die specifieke pagina
- Selecteer SEO (Google) tag
- Zet Deze pagina verbergen in zoekresultaten aan
Hoe het robots.txt-bestand op je Shopify te bewerken
Net als bij Wix voegt Shopify automatisch een niet-bewerkbaar robots.txt-bestand toe aan je site. Als je niet wilt dat sommige pagina's worden geïndexeerd, moet je de “noindex tag” toevoegen of de pagina depubliceren. Je kunt ook meta tags toevoegen in het header-gedeelte van de pagina's die je niet wilt laten indexeren. Dit is wat je aan je header moet toevoegen:
<meta name= “robots” content = “noindex”>
Shopify heeft een uitgebreide gids gemaakt over hoe je pagina's kunt verbergen voor zoekmachines die je kunt volgen.
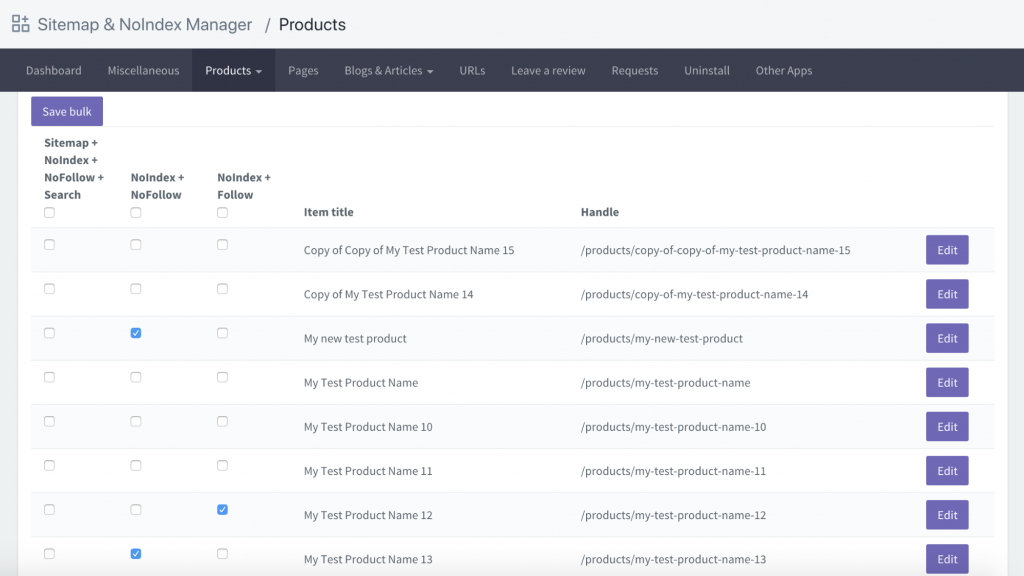
Een andere optie is om een app te downloaden genaamd Sitemap & NoIndex Manager van Orbis Labs. Je kunt eenvoudig de noindex of nofollow opties voor elke pagina op je Shopify site aanvinken: