Denk erover na. Waarom maak je een website? Zodat je potentiële klanten of publiek je gemakkelijk kunnen vinden en zodat je opvalt tussen de concurrentie, toch? Hoe wordt je content eigenlijk gezien? Wordt alle content op je site altijd gezien?
Waarom je alle pagina's op je website moet vinden
Het is mogelijk dat pagina's met waardevolle informatie die daadwerkelijk gezien moet worden, helemaal niet gezien worden. Als dit het geval is voor uw website, dan loopt u waarschijnlijk aanzienlijk verkeer mis, of zelfs potentiële klanten.
Er kunnen ook pagina's zijn die zelden worden gezien, en wanneer ze dat wel zijn, komen gebruikers/bezoekers/potentiële klanten op een dood spoor terecht, omdat ze geen toegang hebben tot andere pagina's. Ze kunnen alleen vertrekken. Dit is net zo erg als die pagina's die nooit worden gezien. Google zal de hoge bouncepercentages beginnen op te merken en de geloofwaardigheid van je site in twijfel trekken. Dit zal ervoor zorgen dat je webpagina's lager en lager gerangschikt worden.
Hoe je content daadwerkelijk wordt gezien

Voor gebruikers, bezoekers of potentiële klanten om uw inhoud te zien, moeten crawlen en indexeren worden gedaan en vaak worden gedaan. Wat is crawlen en indexeren?
Wat is [crawling] en [indexing]?
Voor Google om je inhoud aan gebruikers/bezoekers/potentiële klanten te tonen, moet het eerst weten dat de inhoud bestaat. Hoe dit gebeurt is via crawlen. Dit is wanneer zoekmachines op zoek gaan naar nieuwe inhoud en deze toevoegen aan hun database van reeds bestaande inhoud.
Wat maakt kruipen mogelijk?
- Links
- Sitemaps
- Content Management Systems (CMS - Wix, Blogger)
Links:
Wanneer je een link toevoegt van een bestaande pagina naar een andere nieuwe pagina, bijvoorbeeld via ankertekst, kunnen zoekmachinebots of spiders de nieuwe pagina volgen en toevoegen aan Google’s ‘database’ voor toekomstige referentie.
Sitemaps:
Deze worden ook wel XML Sitemaps genoemd. Hier dient de site-eigenaar een lijst in van al hun pagina's bij de zoekmachine. De webmaster kan ook details opnemen zoals de laatste wijzigingsdatum. De pagina's worden vervolgens gecrawld en toegevoegd aan de ‘database’. Dit is echter niet in real time. Uw nieuwe pagina's of inhoud worden niet gecrawld zodra u uw sitemap indient. Crawlen kan dagen of weken duren.
De meeste sites die een Content Management System (CMS) gebruiken, genereren deze automatisch, dus het is een beetje een snelkoppeling. De enige keer dat een site de sitemap mogelijk niet heeft gegenereerd, is als je een website helemaal opnieuw hebt gemaakt.
CMS:
Als je website wordt aangedreven door een CMS zoals Blogger of Wix, kan de hostingprovider (in dit geval de CMS) ‘zoekmachines vertellen om nieuwe pagina's of inhoud op je website te crawlen.’
Hier is wat informatie om je te helpen met het proces:
Een sitemap toevoegen aan WordPress
Wat is indexeren?
Indexeren in eenvoudige termen is het toevoegen van de gecrawlde pagina's en inhoud aan Google's 'database', die eigenlijk wordt aangeduid als Google's index.
Voordat de inhoud en pagina's aan de index worden toegevoegd, proberen de zoekmachinebots de pagina en de inhoud daarin te begrijpen. Ze gaan zelfs verder met het catalogiseren van bestanden zoals afbeeldingen en video's.
Dit is waarom on-page SEO als webmaster handig is (paginatitels, koppen en gebruik van alt-tekst, onder andere). Wanneer je pagina of pagina's deze aspecten hebben, wordt het gemakkelijker voor Google om je inhoud te 'begrijpen', deze op de juiste manier te catalogiseren en correct te indexeren.
Gebruik van robots.txt
Soms wil je misschien niet dat sommige pagina's of delen van een website worden geïndexeerd. Je moet richtlijnen geven aan zoekmachinebots. Het gebruik van dergelijke richtlijnen maakt ook het crawlen en indexeren gemakkelijker, omdat er minder pagina's worden gecrawld. Lees meer over robots.txt hier.

Gebruik van ‘noindex’
Je kunt ook deze andere richtlijn gebruiken als er pagina's zijn die je niet in de zoekresultaten wilt laten verschijnen. Lees meer over de noindex.
Voordat je begint met het toevoegen van noindex, wil je al je pagina's identificeren zodat je je site kunt opschonen en het voor crawlers gemakkelijker kunt maken om je site correct te crawlen en indexeren.
Wat zijn enkele redenen waarom je al je pagina's moet vinden?
Wat zijn [orphan pages]?
Een [weespagina] kan worden gedefinieerd als een pagina die geen links heeft van andere pagina's op uw site. Dit maakt het bijna onmogelijk voor deze pagina's om gevonden te worden door zoekmachinebots, en daarnaast door gebruikers. Als de bots de pagina niet kunnen vinden, zullen ze deze niet tonen in zoekresultaten, wat de kans verder verkleint dat gebruikers deze vinden.
Hoe ontstaan [orphan pages]?
Wezenpagina's kunnen het gevolg zijn van een poging om inhoud privé te houden, syntaxisfouten, typefouten, dubbele inhoud of verlopen inhoud die niet was gelinkt. Hier zijn meer manieren:
- Testpagina's die werden gebruikt voor A/B-testen en die nooit zijn gedeactiveerd
- Landingspagina's die gebaseerd waren op een seizoen, bijvoorbeeld Kerstmis, Thanksgiving of Pasen
- ‘Vergeten’ pagina's als gevolg van site-migratie
Hoe zit het met doodlopende pagina's?
In tegenstelling tot weespagina's hebben doodlopende pagina's links van andere pagina's op de website, maar linken ze niet naar andere externe sites. Voorbeelden van doodlopende pagina's zijn bedankpagina's, servicepagina's zonder oproepen tot actie, en "niets gevonden" pagina's wanneer gebruikers iets zoeken via de zoekoptie.
Wanneer je doodlopende pagina's hebt, hebben mensen die ze bezoeken slechts twee opties: de site verlaten of teruggaan naar de vorige pagina. Dat betekent dat je aanzienlijk verkeer verliest, vooral als deze pagina's toevallig 'hoofdpagina's' op je website zijn. Nog erger, gebruikers blijven achter met frustratie, verwarring of de vraag, 'wat nu'?
Als gebruikers je site verlaten met een gefrustreerd, verward of enig negatief gevoel, is de kans groot dat ze nooit meer terugkomen, net zoals ontevreden klanten waarschijnlijk nooit meer iets van een merk zullen kopen.
Waar komen doodlopende pagina's vandaan?
Dead end-pagina's zijn het resultaat van pagina's zonder oproepen tot actie. Een voorbeeld hiervan zou een over ons-pagina zijn die verwijst naar de diensten die uw bedrijf aanbiedt, maar geen link naar die diensten heeft. Zodra de lezer begrijpt wat uw bedrijf drijft, de waarden die u hooghoudt, hoe het bedrijf is opgericht en de diensten die u aanbiedt en al enthousiast is, moet u hen vertellen wat ze vervolgens moeten doen.
Een eenvoudige call-to-action knop ‘bekijk onze diensten’ zal het werk doen. Zorg ervoor dat de knop bij het klikken daadwerkelijk de dienstenpagina opent. Je wilt niet dat de gebruiker een 404 krijgt, wat hem/haar ook gefrustreerd zal achterlaten.

Wat zijn verborgen pagina's?
Verborgen pagina's zijn pagina's die niet toegankelijk zijn via een menu of navigatie. Hoewel een bezoeker ze mogelijk kan bekijken, vooral via ankertekst of inbound links, kunnen ze moeilijk te vinden zijn.
Pagina's die in de categorie sectie vallen, zijn waarschijnlijk ook verborgen pagina's, omdat ze zich in het beheerderspaneel bevinden. De zoekmachine heeft mogelijk nooit toegang tot deze pagina's, omdat ze geen toegang hebben tot informatie die in databases is opgeslagen.
Verborgen pagina's kunnen ook het resultaat zijn van pagina's die nooit aan de sitemap van de site zijn toegevoegd maar wel op de server bestaan.
Moeten alle verborgen pagina's worden verwijderd?
Niet echt. Er zijn verborgen pagina's die absoluut noodzakelijk zijn, en die nooit toegankelijk zouden moeten zijn vanuit je navigaties. Laten we naar voorbeelden kijken:
Nieuwsbrief inschrijvingen
Je kunt een pagina hebben die de voordelen van het aanmelden voor de nieuwsbrief uiteenzet, hoe vaak gebruikers deze kunnen verwachten te ontvangen, of een grafiek die de nieuwsbrief (of vorige nieuwsbrief) toont. Vergeet niet om de aanmeldlink ook op te nemen.
Pagina's met gebruikersinformatie
Pagina's die gebruikers vereisen om hun informatie te delen, moeten zeker verborgen worden. Gebruikers moeten accounts aanmaken voordat ze toegang kunnen krijgen. Nieuwsbriefaanmeldingen kunnen hier ook worden gecategoriseerd.
Hoe verborgen pagina's te vinden
Zoals we al zeiden, kun je verborgen pagina's vinden met alle methoden die worden gebruikt om [weespagina's] of doodlopende pagina's te vinden. Laten we er nog een paar verkennen.
Gebruik van robots.txt
Verborgen pagina's zijn zeer waarschijnlijk verborgen voor zoekmachines via robots.txt. Om toegang te krijgen tot de robots.txt van een site, typ [domeinnaam]/robots.txt in een browser en druk op enter. Vervang 'domeinnaam' door de domeinnaam van je site. Let op vermeldingen die beginnen met 'disallow' of 'nofollow'.
Handmatig vinden
Als je bijvoorbeeld producten via je website verkoopt en vermoedt dat een van je productcategorieën verborgen is, kun je er handmatig naar zoeken. Om dit te doen, kopieer en plak je de URL van een ander product en bewerk je deze dienovereenkomstig. Als je het niet vindt, had je gelijk!
Wat als je geen idee hebt wat de verborgen pagina's zouden kunnen zijn? Als je je website in mappen organiseert, kun je je domeinnaam/map-naam toevoegen aan de browser van een site en door de pagina's en submappen navigeren.
Zodra je je verborgen pagina's hebt gevonden (en ze hoeven niet verborgen te blijven zoals hierboven besproken), moet je ze toevoegen aan je sitemap en een crawl-verzoek indienen.
Hoe u alle pagina's op uw site kunt vinden
Je moet al je webpagina's vinden om te weten welke doodlopend of wees zijn. Laten we de verschillende manieren verkennen om dit te bereiken:
Uw sitemapbestand gebruiken
We hebben al naar sitemaps gekeken. Je sitemap zou handig zijn bij het analyseren van al je webpagina's. Als je geen sitemap hebt, kun je een sitemapgenerator gebruiken om er een voor je te genereren. Het enige wat je hoeft te doen is je domeinnaam invoeren en de sitemap wordt voor je gegenereerd.
Uw CMS gebruiken
Als je site wordt aangedreven door een contentmanagementsysteem (CMS) zoals WordPress, en je sitemap bevat niet alle links, is het mogelijk om de lijst van al je webpagina's te genereren vanuit het CMS. Om dit te doen, gebruik een plugin zoals Export All URLs.
Een logboek gebruiken
Een logboek van alle pagina's die aan bezoekers worden geserveerd, is ook handig. Om toegang te krijgen tot het logboek, log in op je cPanel en zoek naar 'raw log files'. Vraag je hostingprovider eventueel om het te delen. Op deze manier kun je de meest bezochte pagina's zien, de nooit bezochte pagina's en die met de hoogste uitvalpercentages. Pagina's met hoge bouncepercentages of geen bezoekers kunnen doodlopende of weespagina's zijn.
Google Analytics gebruiken
Hier zijn de stappen om te volgen:
Stap 1: Log in op je Analytics-pagina.
Stap 2: Ga naar ‘gedrag’ en vervolgens ‘site-inhoud’
Stap 3: Ga naar 'alle pagina's'
Stap 4: Scroll naar de onderkant en kies aan de rechterkant ‘show rows’
Stap 5: Selecteer 500 of 1000, afhankelijk van hoeveel pagina's je denkt dat je site zal hebben
Stap 6: Scroll omhoog en kies rechtsboven ‘exporteren’
Stap 7: Kies ‘exporteren als .xlsx’ (excel)
Stap 8: Zodra het excelbestand is geëxporteerd, kies ‘dataset 1’
Stap 9: Sorteren op ‘unieke paginaweergaven’.
Stap 10: Verwijder alle andere rijen en kolommen behalve degene met je URL's
Stap 11: Gebruik deze formule op de tweede kolom:
=CONCATENEREN(“http://domain.com,A1)
Stap 12: Vervang het domein door het domein van je site. Sleep de formule zodat deze ook op de andere cellen wordt toegepast.
Je hebt nu al je URL's.
Als je ze wilt omzetten in hyperlinks om ze gemakkelijk te kunnen aanklikken en openen wanneer je iets opzoekt, ga dan door naar stap 13.
Stap 13: Gebruik deze formule op de derde rij:
=HYPERLINK(B1)
Sleep de formule zodat deze ook op de andere cellen wordt toegepast.
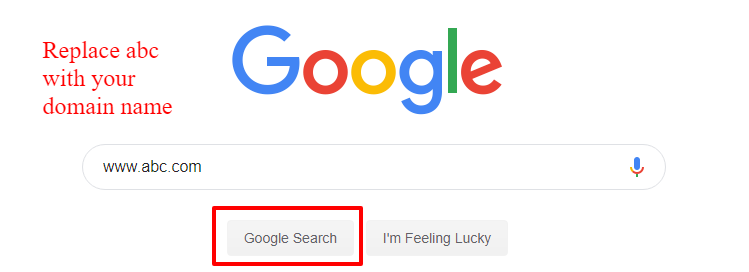
Handmatig typen in de zoekopdracht van Google
Je kunt ook deze site typen: www.abc.com in de zoekopdracht van Google. Vervang ‘abc’ door je domeinnaam. Je krijgt zoekresultaten met alle URL's die Google heeft gecrawld en geïndexeerd, inclusief afbeeldingen, links naar vermeldingen op andere sites, en zelfs hashtags waarmee je merk kan worden gelinkt.
Je kunt ze vervolgens handmatig kopiëren en plakken op een excel-spreadsheet.
Wat doe je dan met je URL-lijst?
Op dit punt vraag je je misschien af wat je moet doen met je URL-lijst. Laten we eens kijken naar de beschikbare opties:
Handmatige vergelijking met loggegevens
Een van de opties zou zijn om handmatig je URL-lijst te vergelijken met het CMS-logboek en de pagina's te identificeren die helemaal geen verkeer lijken te hebben, of die de hoogste bouncepercentages lijken te hebben. Je kunt dan een tool zoals de onze gebruiken om inkomende en uitgaande links te controleren voor elk van de pagina's waarvan je vermoedt dat ze wees of doodlopend zijn.
Een andere benadering is om al je URL's te downloaden als een .xlsx-bestand (excel) en je log ook. Vergelijk ze naast elkaar (in twee kolommen bijvoorbeeld) en gebruik dan de 'duplicaten verwijderen optie' in excel. Volg de stapsgewijze instructies. Aan het einde van het proces heb je alleen nog maar [wees] en doodlopende pagina's over.
De derde vergelijkingsmethode is het kopiëren van twee datasets - je log en URL-lijst naar Google Sheets. Dit stelt je in staat om deze formule te gebruiken: =VLOOKUP(A1, A: B,2,) om URL's op te zoeken die aanwezig zijn in je URL-lijst, maar niet in je log. De ontbrekende pagina's (weergegeven als N/A) moeten worden geïnterpreteerd als [weespagina's]. Zorg ervoor dat de loggegevens in de eerste of linker kolom staan.
Gebruik van site-crawlingtools
De andere optie zou zijn om je URL-lijst te laden op tools die site-crawls kunnen uitvoeren, te wachten tot ze de site hebben gecrawld en vervolgens je URL's te kopiëren en plakken op een spreadsheet voordat je ze één voor één analyseert en probeert uit te zoeken welke [orphan] of [dead end] zijn.
Deze twee opties kunnen tijdrovend zijn, vooral als je veel pagina's op je site hebt, toch?
Nou, wat dacht je van een tool die niet alleen al je URL's vindt, maar je ook in staat stelt om ze te filteren en hun status te tonen (zodat je weet welke doodlopend of wees zijn?). Met andere woorden, als je een snelkoppeling wilt om alle pagina's van je site te vinden, SEOptimer's SEO Crawl Tool.
SEOptimer's SEO Crawl Tool
Deze tool stelt je in staat om toegang te krijgen tot alle pagina's van je site. Je kunt beginnen door naar “Website Crawls” te gaan en je website url in te voeren. Klik op “Crawl”
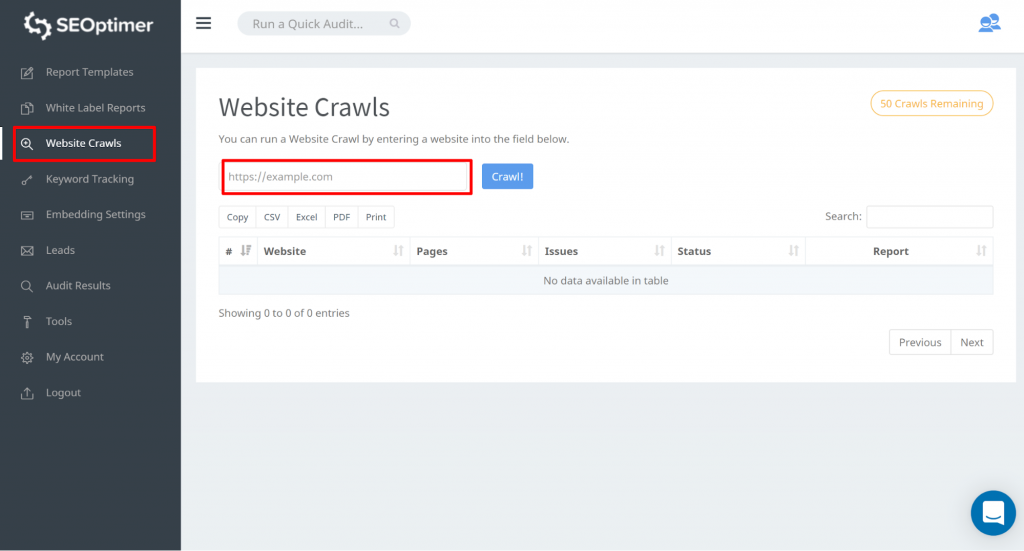
Zodra de crawl is voltooid, kun je klikken op “Rapport bekijken”:
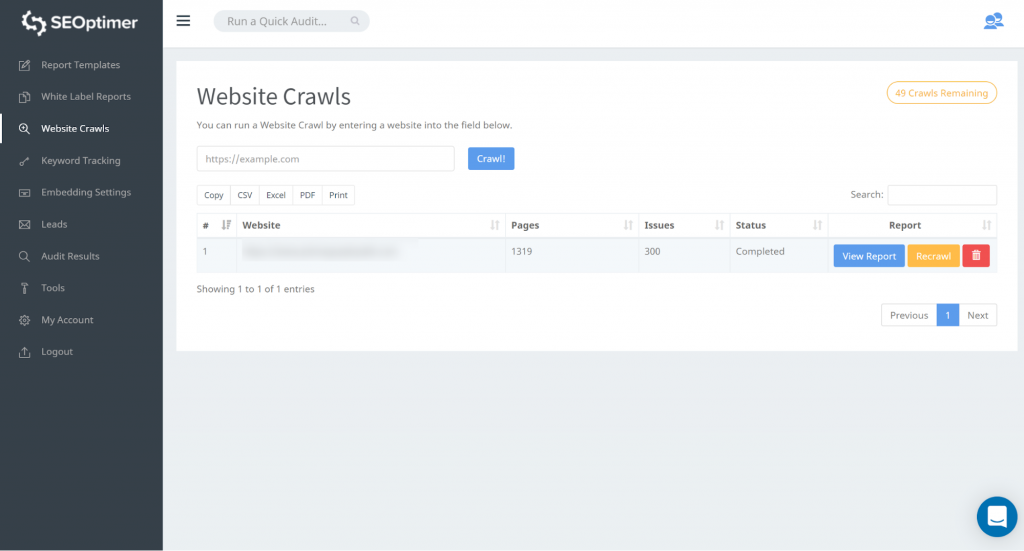
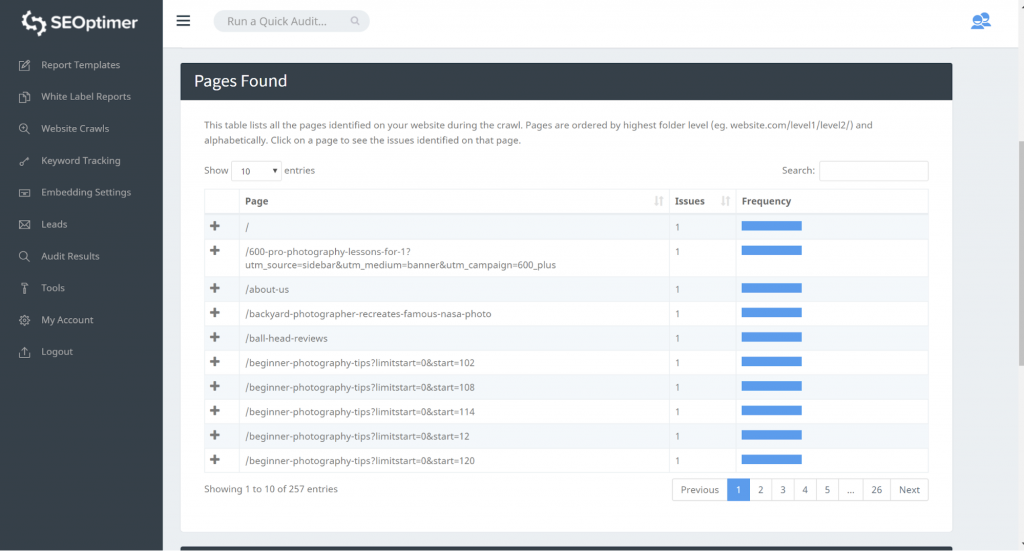
Onze crawltool detecteert alle pagina's van uw website en vermeldt ze in de “Pagina Gevonden” sectie van de crawl.
Je kunt “404 Error” problemen identificeren op onze “Issues Found” net onder de “Pages Found” sectie:
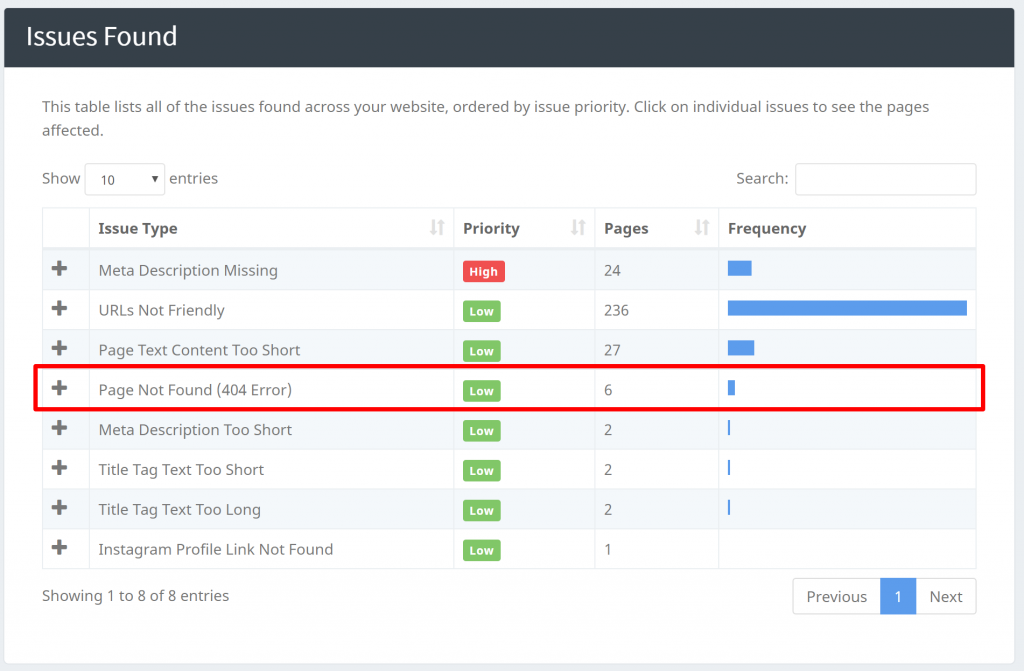
Onze crawlers kunnen andere problemen identificeren zoals het vinden van pagina's met ontbrekende Titel, Meta Beschrijvingen, enz. Zodra je al je pagina's hebt gevonden, kun je beginnen met filteren en werken aan de [problemen] die voorhanden zijn.
Concluderend
In dit artikel hebben we gekeken naar hoe je alle pagina's op je site kunt vinden en waarom het belangrijk is. We hebben ook concepten zoals [weespagina's] en [doodlopende pagina's], evenals verborgen pagina's verkend. We hebben elk onderscheiden, hoe je elk kunt identificeren tussen je URL's. Er is geen beter moment om erachter te komen of je verlies lijdt door verborgen, [weespagina's] of [doodlopende pagina's].