Co to jest Robots.txt?
Robots.txt to plik w formie tekstowej, który instruuje boty indeksujące, aby indeksowały lub nie indeksowały pewnych stron. Jest również znany jako strażnik całej twojej witryny. Pierwszym celem botów indeksujących jest znalezienie i odczytanie pliku robots.txt, zanim uzyskają dostęp do twojej mapy witryny lub jakichkolwiek stron lub folderów.
Za pomocą robots.txt możesz bardziej szczegółowo:
- Reguluj, jak boty wyszukiwarek przeszukują Twoją stronę
- Zapewnij określony dostęp
- Pomóż robotom wyszukiwarek indeksować zawartość strony
- Pokaż, jak dostarczać treści użytkownikom
Robots.txt jest częścią Protokołu Wykluczenia Robotów (R.E.P), składającą się z dyrektyw na poziomie strony/strony/URL. Chociaż roboty wyszukiwarek mogą nadal przeszukiwać całą twoją witrynę, to od ciebie zależy, czy pomożesz im zdecydować, czy niektóre strony są warte czasu i wysiłku.
Dlaczego potrzebujesz Robots.txt
Twoja strona nie potrzebuje pliku robots.txt, aby działała poprawnie. Główne powody, dla których potrzebujesz pliku robots.txt, to taki, że kiedy boty przeszukują Twoją stronę, proszą o pozwolenie na przeszukanie, aby mogły próbować odzyskać informacje o stronie do indeksowania. Ponadto, strona internetowa bez pliku robots.txt w zasadzie prosi boty indeksujące o zindeksowanie strony według własnego uznania. Ważne jest, aby zrozumieć, że boty będą nadal przeszukiwać Twoją stronę bez pliku robots.txt.
Lokalizacja twojego pliku robots.txt jest również ważna, ponieważ wszystkie boty będą szukać www.123.com/robots.txt. Jeśli tam niczego nie znajdą, będą zakładać, że strona nie posiada pliku robots.txt i zaindeksują wszystko. Plik musi być plikiem tekstowym w formacie ASCII lub UTF-8. Ważne jest również zaznaczenie, że reguły są wrażliwe na wielkość liter.
Oto niektóre rzeczy, które robots.txt wykona i nie wykona:
- Plik umożliwia kontrolowanie dostępu robotów do określonych obszarów twojej strony internetowej. Musisz być bardzo ostrożny podczas konfigurowania robots.txt, ponieważ istnieje możliwość zablokowania indeksowania całej strony.
- Zapobiega indeksowaniu i pojawianiu się zduplikowanych treści w wynikach wyszukiwania.
- Plik określa opóźnienie przeszukiwania w celu zapobieżenia przeciążeniu serwerów, gdy roboty ładują wiele treści jednocześnie.
Oto kilka Googlebotów, które mogą od czasu do czasu przeszukiwać Twoją stronę:
| Web Crawler | Ciąg User-Agent |
| Wiadomości Googlebot | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Wideo | Googlebot-Video/1.0 |
| Google Mobile (telefon z funkcjami) | SAMSUNG-SGH-E250/1.0 Profil/MIDP-2.0 Konfiguracja/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (kompatybilny; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Smartfon Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, jak Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatybilny; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (kompatybilny; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (jakość strony docelowej PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (pobiera zasoby dla urządzeń mobilnych) | AdsBot-Google-Mobile-Apps |
Możesz znaleźć listę dodatkowych botów tutaj.
- Pliki pomagają w określeniu lokalizacji map witryny.
- Zapobiega to również indeksowaniu przez roboty wyszukiwarek różnych plików na stronie internetowej, takich jak obrazy i pliki PDF.
Gdy bot chce odwiedzić Twoją stronę internetową (na przykład, www.123.com), na początku sprawdza www.123.com/robots.txt i znajduje:
User-agent: *
Disallow: /
Ten przykład instruuje wszystkie (User-agents*) boty wyszukiwarek, aby nie indeksowały (Disallow: /) strony internetowej.
Jeśli usuniesz ukośnik z Disallow, jak w poniższym przykładzie,
User-agent: *
Zabronione:
bots będą mogły przeszukiwać i indeksować wszystko na stronie internetowej. Dlatego ważne jest, aby zrozumieć składnię robots.txt.
Zrozumienie składni robots.txt
Składnia pliku robots.txt może być postrzegana jako "język" plików robots.txt. Istnieje 5 powszechnych terminów, które prawdopodobnie napotkasz w pliku robots.txt. Są to:
- User-agent: Specyficzny robot internetowy, któremu udzielasz instrukcji przeszukiwania (zazwyczaj wyszukiwarka). Listę większości agentów użytkownika można znaleźć tutaj.
- Disallow: Polecenie używane do zakazania agentowi użytkownika indeksowania określonego adresu URL. Tylko jedna linia "Disallow:" jest dozwolona dla każdego adresu URL.
- Allow (Dotyczy tylko Googlebot): Polecenie informuje Googlebot, że może uzyskać dostęp do strony lub podkatalogu, nawet jeśli nadrzędna strona lub podkatalog jest zabroniony.
- Crawl-delay: Liczba milisekund, jaką robot indeksujący powinien odczekać przed załadowaniem i przeszukaniem zawartości strony. Należy zauważyć, że Googlebot nie uznaje tego polecenia, ale częstotliwość indeksowania może być ustawiona w Google Search Console.
- Mapa witryny: Służy do wskazania lokalizacji dowolnej mapy witryny XML powiązanej z adresem URL. Zauważ, że to polecenie jest obsługiwane tylko przez Google, Ask, Bing i Yahoo.
Wyniki instrukcji Robots.txt
Oczekujesz trzech wyników, gdy wydajesz instrukcje robots.txt:
- Pełne zezwolenie
- Pełne zakazanie
- Warunkowe zezwolenie
Przeanalizujmy każdy z nich poniżej.
Pełne zezwolenie
Ten wynik oznacza, że cała zawartość na twojej stronie internetowej może być przeszukiwana. Pliki robots.txt są przeznaczone do blokowania przeszukiwania przez boty wyszukiwarek, więc ta komenda może być bardzo ważna.
Ten wynik może oznaczać, że na Twojej stronie internetowej w ogóle nie ma pliku robots.txt. Nawet jeśli go nie masz, roboty wyszukiwarek i tak będą go szukać na Twojej stronie. Jeśli go nie znajdą, wówczas przeanalizują wszystkie części Twojej witryny.
Inna opcja w ramach tego wyniku to stworzenie pliku robots.txt, ale pozostawienie go pustego. Gdy robot przyjdzie indeksować, zidentyfikuje i nawet przeczyta plik robots.txt. Ponieważ nie znajdzie tam nic, przejdzie do indeksowania reszty witryny.
Jeśli masz plik robots.txt i zawiera on następujące dwie linie,
User-agent:*
Zabronione:
wyszukiwarka spider przejdzie przez Twoją stronę internetową, zidentyfikuje plik robots.txt i go przeczyta. Dotrze do linii drugiej, a następnie przejdzie do przeszukiwania reszty witryny.
Pełne blokowanie
Tutaj, żadna zawartość nie zostanie przeszukana i zindeksowana. Polecenie to jest wydane przez tę linię:
User-agent:*
Disallow:/
Gdy mówimy o braku treści, mamy na myśli to, że nic z witryny (treści, strony itp.) nie może być przeszukiwane. To nigdy nie jest dobry pomysł.
Warunkowe Zezwolenie
To oznacza, że tylko niektóre treści na stronie internetowej mogą być indeksowane.
Warunkowe zezwolenie ma ten format:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Pełną składnię robots.txt znajdziesz tutaj.
Zauważ, że zablokowane strony mogą być nadal indeksowane, nawet jeśli zabronisz URL, jak pokazano na obrazku poniżej:
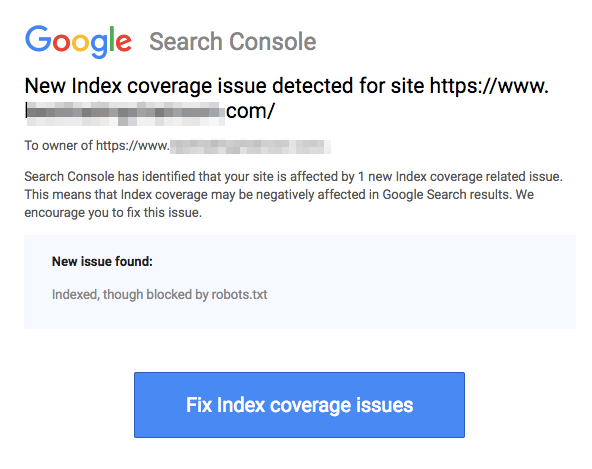
Możesz otrzymać email od wyszukiwarek, że Twój URL został zindeksowany, jak na zrzucie ekranu powyżej. Jeśli Twój zabroniony URL jest linkowany z innych stron, takich jak tekst kotwicy w linkach, zostanie zindeksowany. Rozwiązaniem tego jest 1) zabezpieczenie hasłem Twoich plików na serwerze, 2) użycie meta tagu noindex, lub 3) całkowite usunięcie strony.
Czy robot może nadal skanować i ignorować mój plik robots.txt?
Tak. Jest możliwe, że robot może zignorować plik robots.txt. Wynika to z faktu, że Google wykorzystuje inne czynniki, takie jak zewnętrzne informacje i przychodzące linki, aby określić, czy strona powinna być indeksowana, czy nie. Jeśli nie chcesz, aby strona była w ogóle indeksowana, powinieneś użyć meta tagu robots noindex. Inną opcją byłoby użycie nagłówka HTTP X-Robots-Tag.
Czy mogę zablokować tylko złe roboty?
Teoretycznie jest możliwe zablokowanie złych robotów, ale w praktyce może być to trudne do wykonania. Spójrzmy na kilka sposobów, aby to zrobić:
- Możesz zablokować złego robota, wykluczając go. Musisz jednak znać nazwę, pod którą dany robot skanuje w polu User-Agent. Następnie musisz dodać sekcję w swoim pliku robots.txt, która wyklucza złego robota.
- Konfiguracja serwera. To zadziała tylko w przypadku, gdy działanie złego robota pochodzi z jednego adresu IP. Konfiguracja serwera lub sieciowego firewalla zablokuje złemu robotowi dostęp do twojego serwera internetowego.
- Korzystanie z zaawansowanych konfiguracji reguł zapory sieciowej. Te automatycznie zablokują dostęp do różnych adresów IP, na których istnieją kopie złego robota. Dobrym przykładem botów działających na różnych adresach IP jest przypadek przejętych komputerów PC, które mogą nawet być częścią większej sieci Botnet (dowiedz się więcej o Botnet tutaj).
Jeśli zły robot działa z pojedynczego adresu IP, możesz zablokować jego dostęp do twojego serwera internetowego poprzez konfigurację serwera lub za pomocą zapory sieciowej.
Jeśli kopie robota działają pod wieloma różnymi adresami IP, wówczas staje się trudniejsze ich zablokowanie. Najlepszą opcją w tym przypadku jest użycie zaawansowanych konfiguracji reguł zapory sieciowej, które automatycznie blokują dostęp do adresów IP, które nawiązują wiele połączeń; niestety, może to wpłynąć również na dostęp dobrych botów.
Jakie są najlepsze praktyki SEO przy użyciu robots.txt?
W tym momencie możesz się zastanawiać, jak poruszać się po tych bardzo zdradliwych wodach robots.txt. Spójrzmy na to bardziej szczegółowo:
- Upewnij się, że nie blokujesz żadnych treści lub sekcji swojej strony, które chcesz, aby były przeszukiwane.
- Użyj mechanizmu blokującego innego niż robots.txt, jeśli chcesz, aby wartość linku była przekazywana ze strony z robots.txt (co oznacza, że jest ona praktycznie zablokowana) do miejsca docelowego linku.
- Nie używaj robots.txt, aby zapobiec pojawianiu się w wynikach wyszukiwania wrażliwych danych, takich jak prywatne informacje użytkowników. Może to spowodować, że inne strony będą linkować do stron zawierających prywatne informacje użytkowników, co może spowodować zindeksowanie strony. W takim przypadku robots.txt został ominięty. Inne opcje, które możesz rozważyć, to ochrona hasłem lub dyrektywa noindex meta.
- Nie ma potrzeby określania dyrektyw dla każdego z robotów wyszukiwarki, ponieważ większość agentów użytkownika, jeśli należy do tej samej wyszukiwarki, podąża za tymi samymi zasadami. Google używa Googlebot dla wyszukiwarek i Googlebot Image dla wyszukiwania obrazów. Jedyną zaletą umiejętności określania każdego robota jest możliwość dokładnego dostrojenia sposobu, w jaki treści na twojej stronie są indeksowane.
- Jeśli zmieniłeś plik robots.txt i chcesz, aby Google zaktualizował go szybciej, prześlij go bezpośrednio do Google. Aby uzyskać instrukcje, jak to zrobić, kliknij tutaj. Ważne jest, aby zauważyć, że wyszukiwarki przechowują zawartość robots.txt w pamięci podręcznej i aktualizują przechowywaną zawartość przynajmniej raz dziennie.
Podstawowe wytyczne dotyczące pliku robots.txt
Teraz, gdy masz podstawowe zrozumienie SEO w odniesieniu do robots.txt, jakie rzeczy powinieneś mieć na uwadze podczas używania robots.txt? W tej sekcji przyjrzymy się kilku wytycznym, których należy przestrzegać podczas używania robots.txt, chociaż ważne jest, aby faktycznie przeczytać całą składnię.
Format i lokalizacja
Edytor tekstu, którego wybierzesz do stworzenia pliku robots.txt, musi być w stanie tworzyć standardowe pliki tekstowe ASCII lub UTF-8. Używanie edytora tekstu jest złym pomysłem, ponieważ mogą zostać dodane niektóre znaki, które mogą wpłynąć na indeksowanie.
Podczas gdy prawie każdy edytor tekstu może być użyty do stworzenia twojego pliku robots.txt, to narzędzie jest wysoce polecane, ponieważ pozwala na testowanie względem twojej strony.
Oto więcej wytycznych dotyczących formatu i lokalizacji:
- Musisz nazwać tworzony plik "robots.txt", ponieważ nazwa pliku jest wrażliwa na wielkość liter. Nie używa się wielkich liter.
- Możesz mieć tylko jeden plik robots.txt na całej stronie.
- Plik robots.txt znajduje się tylko w jednym miejscu: w katalogu głównym hosta strony internetowej, do którego jest stosowany. Zauważ, że nie może być umieszczony w podkatalogu. Jeśli twoja strona internetowa jesthttp://www.123.com/, wówczas lokalizacja pliku robots.txt to http://www.123.com/robots.txt, nie http://www.123.com/pages/robots.txt. Należy zauważyć, że plik robots.txt może być stosowany do subdomen (http://website.123.com/robots.txt) i nawet niestandardowe porty, takie jakhttp://www.123.com: 8181/robots.txt.
Jak wspomniano wcześniej, robots.txt nie jest najlepszym sposobem, aby zapobiec indeksowaniu wrażliwych danych osobowych. Jest to ważna kwestia, szczególnie teraz, po niedawnym wdrożeniu RODO. Prywatność danych nie powinna być naruszana. Kropka.
Jak więc zapewnić, że robots.txt nie wyświetla wrażliwych danych w wynikach wyszukiwania?
Korzystanie z oddzielnego podkatalogu, który jest „nie do wylistowania” w sieci, zapobiegnie rozpowszechnianiu wrażliwych materiałów. Możesz upewnić się, że jest on „nie do wylistowania”, używając konfiguracji serwera. Po prostu przechowuj wszystkie pliki, których nie chcesz, aby robots.txt odwiedzał i indeksował, w tym podkatalogu.
Czy umieszczanie stron lub katalogów w pliku robots.txt nie prowadzi do niezamierzonego dostępu?
Jak wspomniano wcześniej, umieszczenie wszystkich plików, których nie chcesz indeksować, w oddzielnym podkatalogu, a następnie uczynienie go niemożliwym do wylistowania poprzez konfiguracje serwera, powinno zapewnić, że nie pojawią się one w wynikach wyszukiwania. Jedynym wpisem, który wtedy wykonasz w pliku robots.txt, jest nazwa katalogu. Jedyny sposób dostępu do tych plików to bezpośredni link do jednego z plików.
Oto przykład:
Zamiast
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Użyj
User-Agent:*
Disallow:/norobots/
Następnie musisz utworzyć katalog „norobots”, który zawiera foo.html i bar.html. Zwróć uwagę, że konfiguracje twojego serwera muszą być jasne co do niegenerowania listingu katalogów dla katalogu „norobots”.
This may not be a very secure approach because the person or bot attacking your site can still see that you have a “norobots” directory even though they may not be able to view the files inside the directory. However, someone could publish a link to those files on their website or, worse still, the link may show up in a log file that is accessible to the public (e.g. a web server log as a referrer). A server misconfiguration is also possible, resulting in a directory listing.
Co to znaczy? Robots.txt nie może pomóc ci w kontrolowaniu dostępu z prostej przyczyny, że nie jest do tego przeznaczony. Dobrym przykładem jest „Znak zakazu wstępu”. Są ludzie, którzy i tak naruszą tę instrukcję.
Jeśli istnieją pliki, do których dostęp powinny mieć tylko osoby upoważnione, konfiguracje serwera pomogą w uwierzytelnianiu. Jeśli używasz CMS (System Zarządzania Treścią), masz kontrolę dostępu do poszczególnych stron i zbiorów zasobów.
Czy możesz zoptymalizować robots.txt pod kątem SEO?
Oczywiście. Najlepszym przewodnikiem, jak zoptymalizować robots.txt, jest zawartość strony. Szybkie przypomnienie: Robots.txt nigdy nie powinien być używany do blokowania stron przed indeksowaniem przez boty wyszukiwarek. Używaj go tylko do blokowania sekcji twojej strony internetowej, które nie są dostępne dla publiczności, na przykład stron logowania takich jak wp-admin.
To jest linia disallow dla strony logowania Neil Patel na jednej z jego stron internetowych:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Możesz użyć tej linii disallow, aby zablokować indeksowanie twojego logowania.
Jeśli istnieją konkretne strony, których nie chcesz indeksować, użyj tego samego polecenia co powyżej. Przykład:
User-agent:*
Disallow:/page/
Określ stronę, której nie chcesz indeksować, po ukośniku i zamknij kolejnym ukośnikiem. Na przykład:
User-agent:*
Disallow:/page/dziękuję/
Jakie są niektóre strony, które możesz chcieć wykluczyć z indeksowania?
- Zduplikowana treść, która jest zamierzona. Co to oznacza? Czasami celowo tworzysz zduplikowaną treść, aby osiągnąć określony cel. Dobrym przykładem jest wersja strony internetowej przyjazna dla drukarek. Możesz użyć robots.txt, aby zablokować indeksowanie wersji przyjaznej dla drukarek tej samej treści.
- Strony podziękowania. Powód, dla którego chcesz zablokować indeksowanie tej strony jest prosty: Ma to być ostatni krok w lejku sprzedażowym. Do momentu, gdy Twoi odwiedzający dotrą na tę stronę, powinni przejść przez cały lejek sprzedażowy. Jeśli ta strona zostanie zindeksowana, oznacza to, że możesz stracić potencjalnych klientów lub otrzymać fałszywe dane kontaktowe.
Polecenie do zablokowania takiej strony to:
Disallow:/thank-you/
Noindex i NoFollow
Jak wspominaliśmy w całym tym artykule, używanie robots.txt nie jest 100% gwarancją, że twoja strona nie zostanie zindeksowana. Przyjrzyjmy się dwóm sposobom, aby upewnić się, że twoja zablokowana strona faktycznie nie zostanie zindeksowana.
Dyrektywa noindex
To działa w połączeniu z komendą disallow. Użyj obu w swojej dyrektywie, jak w:
Disallow:/thank-you/
Dyrektywa nofollow
To działa, aby specjalnie poinstruować boty Google, aby nie przeszukiwały linków na stronie. To nie jest część pliku robots.txt. Aby użyć komendy nofollow, aby zablokować strony przed przeszukiwaniem i indeksowaniem, musisz znaleźć kod źródłowy konkretnej strony, której nie chcesz indeksować.
Wklej to pomiędzy otwierającym a zamykającym tagiem head:
<meta name = “robots” content=”nofollow”>
Możesz użyć jednocześnie “nofollow” i “noindex”. Użyj tej linii kodu:
<meta name = “robots” content=”noindex,nofollow”>
Generowanie pliku robots.txt
Jeśli uważasz, że trudno jest napisać robots.txt, używając wszystkich niezbędnych formatów i składni, które musisz zrozumieć i stosować, możesz użyć narzędzi, które upraszczają ten proces. Dobrym przykładem jest nasz darmowy generator robots.txt.
To narzędzie pozwala wybrać rodzaj wyniku, którego potrzebujesz na swojej stronie internetowej oraz plik lub katalogi, które chcesz dodać. Możesz nawet przetestować swój plik i zobaczyć, jak radzi sobie twoja konkurencja.
Testowanie pliku robots.txt
Musisz przetestować swój plik robots.txt, aby upewnić się, że działa zgodnie z oczekiwaniami.
Użyj testera robots.txt od Google.
Aby to zrobić, zaloguj się na swoje konto Webmastera.
- Następnie wybierz swoją własność. W tym przypadku jest to twoja strona internetowa.
- Kliknij na "crawl" w lewym pasku bocznym.
- Kliknij na "robots.txt tester".
- Zastąp istniejący kod nowym plikiem robots.txt.
- Kliknij "test".
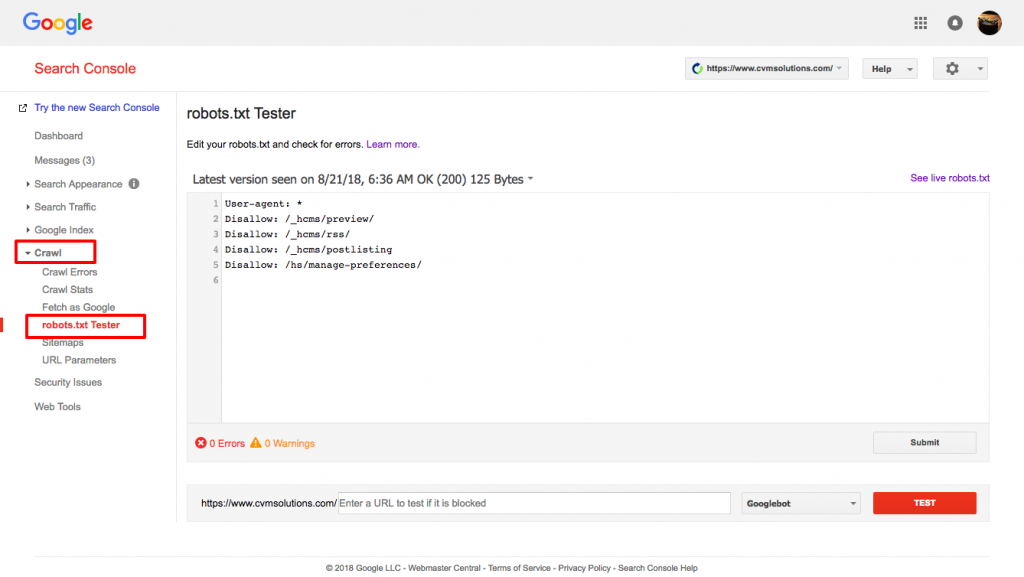
Powinieneś być w stanie zobaczyć pole tekstowe „dozwolone”, jeśli plik jest prawidłowy. Po więcej informacji, zapoznaj się z tym szczegółowym przewodnikiem do testera Google robots.txt.
Jeśli twój plik jest prawidłowy, teraz jest czas, aby przesłać go do katalogu głównego lub zapisać go tam, jeśli istnieje inny plik robots.txt.
Jak dodać plik robots.txt do Twojej strony WordPress
Aby dodać plik robots.txt do twojego pliku WordPress, omówimy opcje związane z wtyczką i FTP.
Dla opcji wtyczki, możesz użyć pluginu takiego jak All in One SEO Pack
Aby to zrobić, zaloguj się do swojego kokpitu WordPress
Przewiń w dół, aż dojdziesz do "plugins"
Kliknij „dodaj nowy”
Przejdź do "wyszukaj wtyczki"
Wpisz „All in One SEO Pack”
Zainstaluj to i aktywuj
W sekcji Ustawienia Ogólne wtyczki All in One SEO, możesz skonfigurować reguły noindex i nofollow, które mają być uwzględnione w twoim pliku robots.txt.
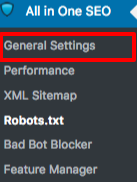
Możesz określić, które adresy URL powinny być NOINDEX, NOFOLLOW. Pozostawienie tych opcji niezaznaczonych będzie domyślnie oznaczało indeksowanie:
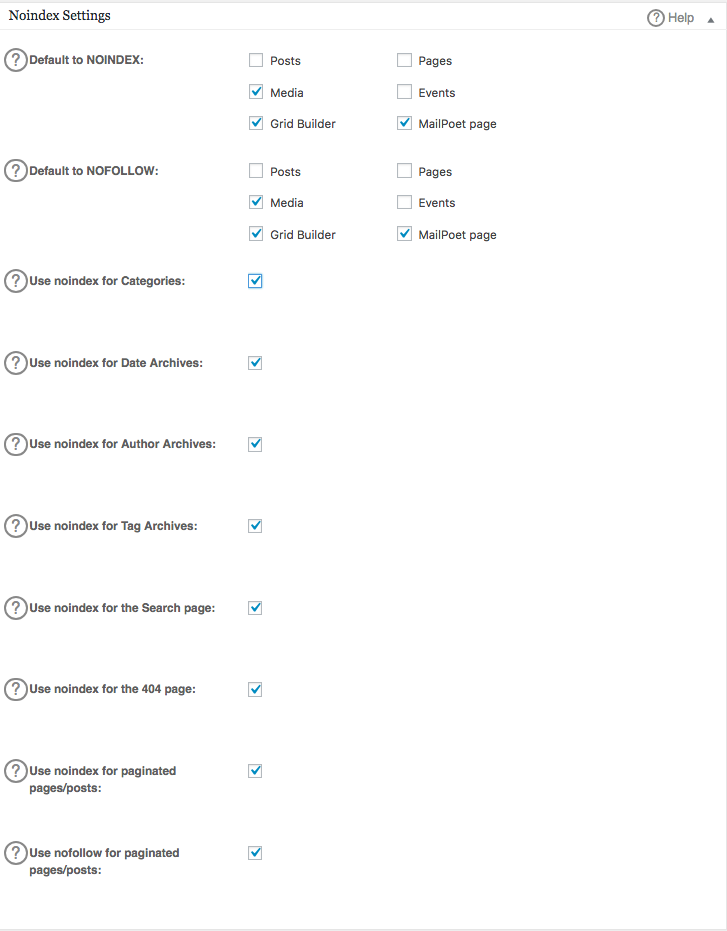
Aby utworzyć zaawansowane reguły w pliku robots.txt, kliknij menedżera funkcji, a następnie przycisk aktywacji znajdujący się poniżej robots.txt.
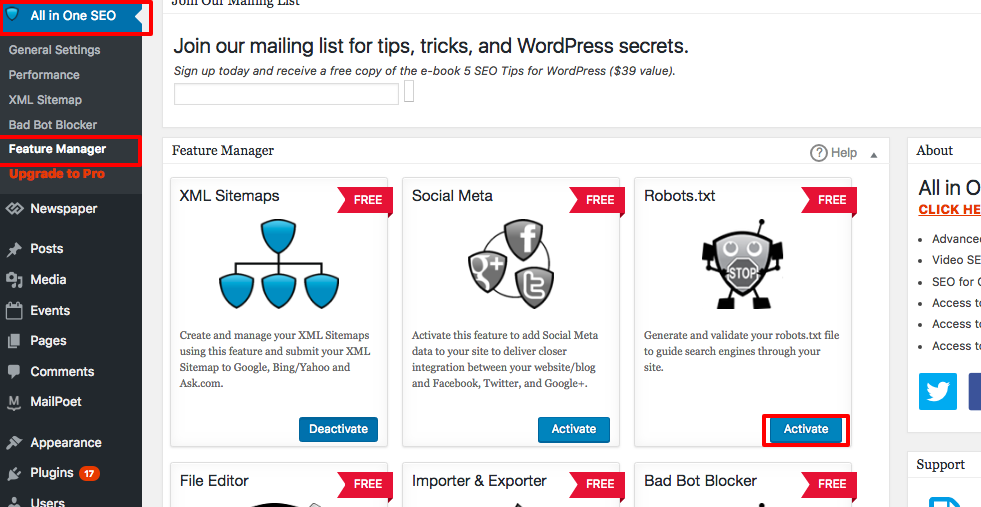
Robots.txt pojawia się teraz tuż poniżej menedżera funkcji. Kliknij na to. Zobaczysz sekcję o nazwie „utwórz plik robots.txt”.
Istnieje sekcja konstruktora reguł, która pozwala wybrać i wypełnić reguły, które chcesz zastosować na swojej stronie, w zależności od tego, co chcesz, aby nie było indeksowane.
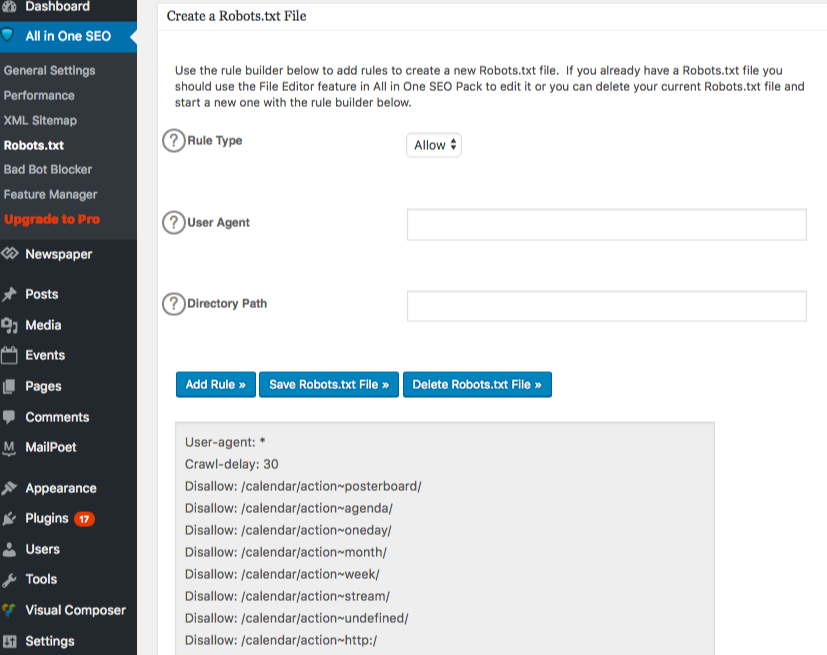
Gdy już skończysz tworzyć regułę, kliknij „dodaj regułę”.
Zasada zostanie następnie wymieniona w utworzonym folderze robots.txt.
Zobaczysz wiadomość informującą, że „Wszystkie opcje w jednym” zostały zaktualizowane.
Inną metodą, której możesz użyć, jest bezpośrednie przesłanie pliku robots.txt do twojego klienta FTP (File Transfer Protocol) takiego jak FileZilla.
Gdy już wygenerujesz swój plik robots.txt, możesz go zlokalizować i zastąpić. Twój plik robots.txt będzie znajdować się w: "/applications/[NAZWA FOLDERU]/public_html."
Jak edytować plik robots.txt na twoim Wix
Wix generuje plik robots.txt dla stron internetowych korzystających z platformy do tworzenia stron internetowych. Aby go zobaczyć, dodaj "/robots.txt" do swojej domeny. Pliki dodane do robots.txt mają związek ze strukturą stron Wix, na przykład linki noflashhtml, które nie przyczyniają się do wartości SEO Twojej strony opartej na Wix.
Nie możesz edytować pliku robots.txt, jeśli Twoja strona jest obsługiwana przez Wix. Możesz jedynie użyć innych opcji, takich jak dodanie "tagu noindex" do stron, których nie chcesz, aby były indeksowane.
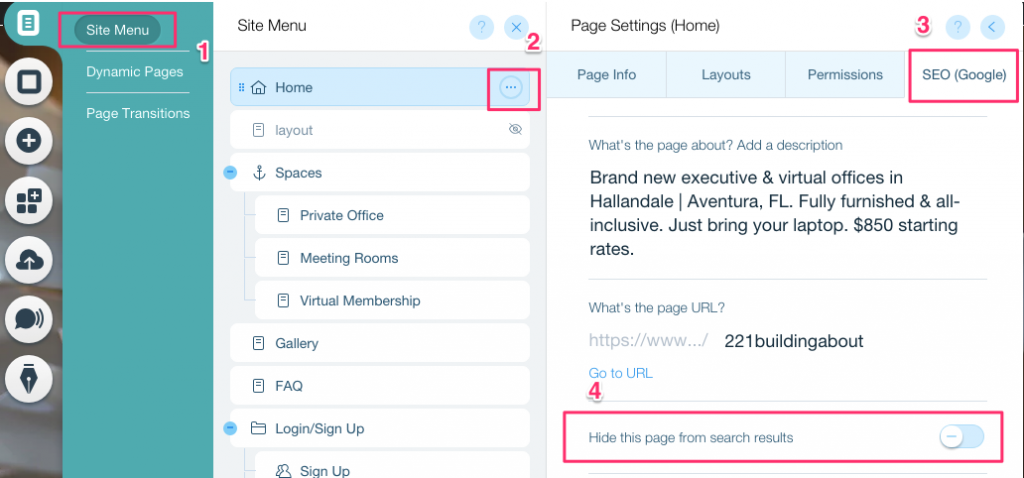
Aby utworzyć tag noindex dla konkretnej strony:
- Kliknij na Menu witryny
- Kliknij na opcję Ustawienia dla tej konkretnej strony
- Wybierz Tag SEO (Google)
- Włącz Ukryj tę stronę przed wynikami wyszukiwania
Jak edytować plik robots.txt na twoim Shopify
Tak samo jak w przypadku Wix, Shopify automatycznie dodaje nieedytowalny plik robots.txt do Twojej strony. Jeśli nie chcesz, aby niektóre strony były indeksowane, musisz dodać "tag noindex" lub usunąć stronę z publikacji. Możesz również dodać meta tagi w sekcji nagłówka stron, których nie chcesz, aby były indeksowane. Oto co powinieneś dodać do swojego nagłówka:
<meta name= “robots” content = “noindex”>
Shopify stworzył dokładny przewodnik, jak ukryć strony przed wyszukiwarkami, którego możesz się trzymać.
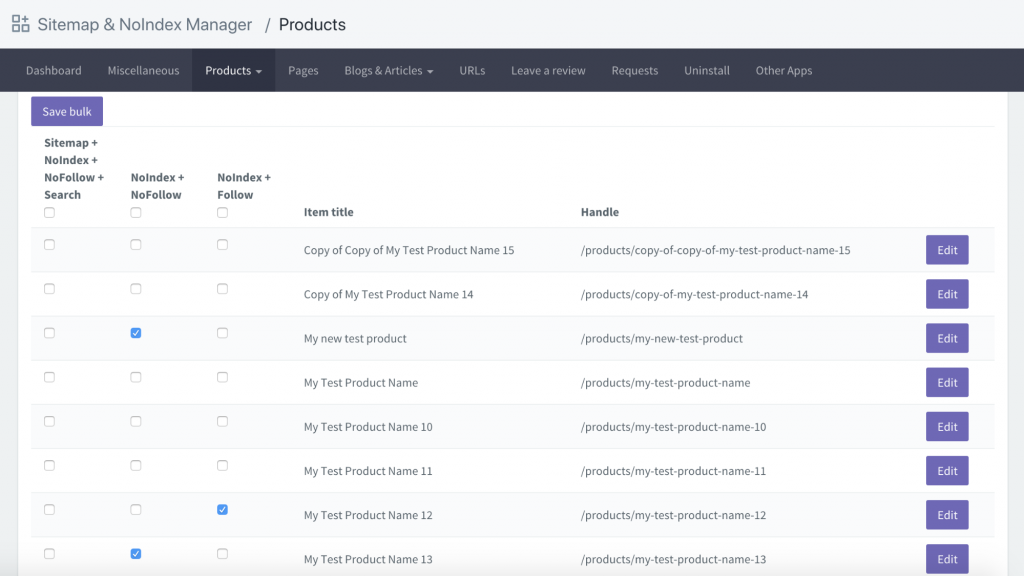
Inna opcja to pobranie aplikacji o nazwie Sitemap & NoIndex Manager autorstwa Orbis Labs. Możesz po prostu zaznaczyć opcje noindex lub nofollow dla każdej strony na swojej witrynie Shopify: