Eğer Google Search Console'da ‘Indexed, though blocked by robots.txt’ uyarısını aldıysanız, bunu mümkün olan en kısa sürede düzeltmek isteyeceksiniz, çünkü bu durum sayfalarınızın Arama Motoru Sonuç Sayfaları'nda (SERPS) sıralanma yeteneğini etkiliyor olabilir.
Bir robots.txt dosyası, web sitenizin dizininde bulunan ve Arama Motoru Tarayıcılarına, örneğin Google'ın botuna, hangi dosyaların görüntülenmesi gerektiği ve hangilerinin görüntülenmemesi gerektiği konusunda bazı talimatlar sunan bir dosyadır.
‘Indexed, though blocked by robots.txt’ ifadesi, Google'ın sayfanızı bulduğunu, ancak robots dosyanızda onu yok sayan bir talimat bulduğunu gösterir (bu, sonuçlarda gözükmemesi anlamına gelir).
Bazen bu kasıtlıdır, ya da aşağıda açıklanan bir dizi nedenle kazara olabilir ve düzeltilebilir.
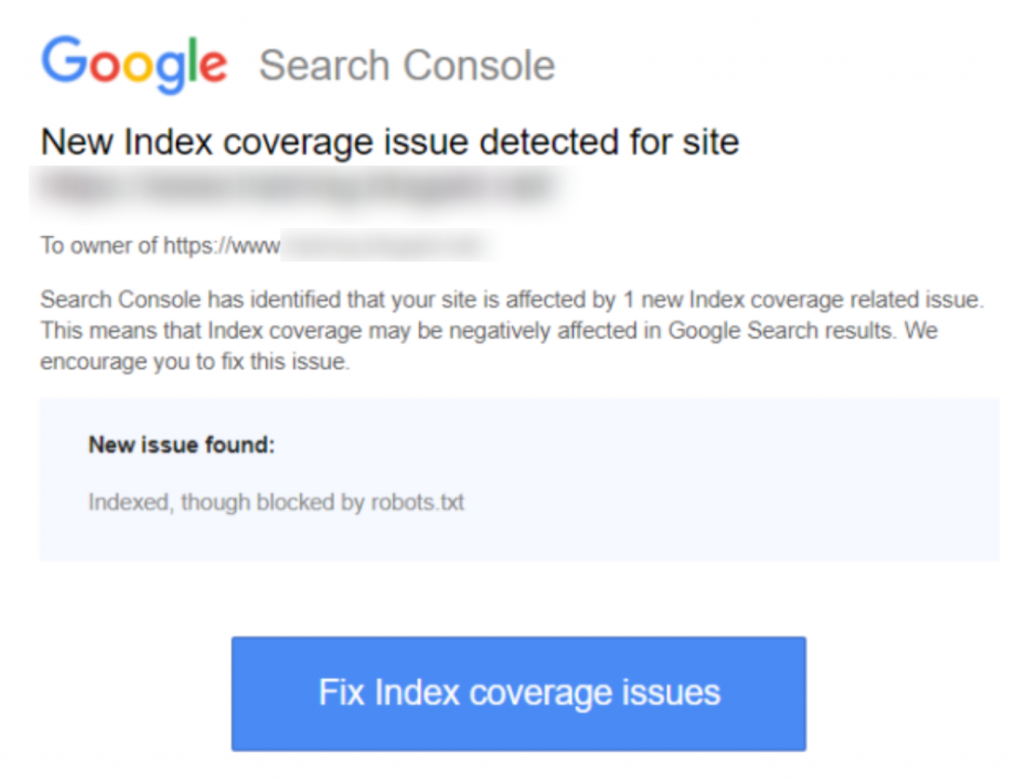
İşte bildirimin ekran görüntüsü:
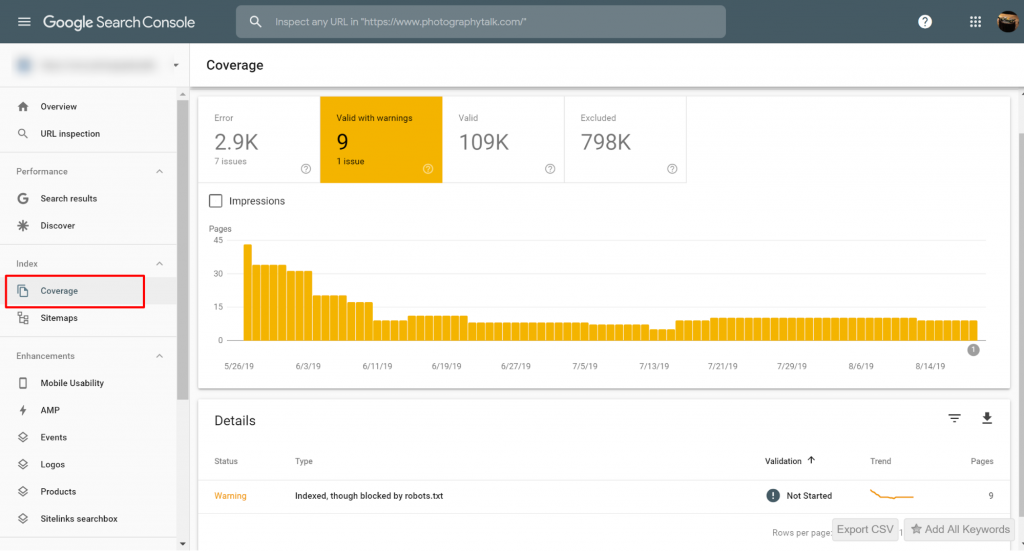
Etkilenen sayfa(lar)ı veya URL(ler)i belirleyin
Eğer Google Search Console (GSC)'den bir bildirim aldıysanız, söz konusu olan belirli sayfa(lar)ı veya URL(ler)i tespit etmeniz gerekmektedir.
Google Search Console>>Kapsam bölümünde, robots.txt tarafından engellenmiş olsa da İndekslenmiş sorunları olan sayfaları görüntüleyebilirsiniz. Uyarı etiketini görmüyorsanız, o zaman serbestsiniz ve temizsiniz.
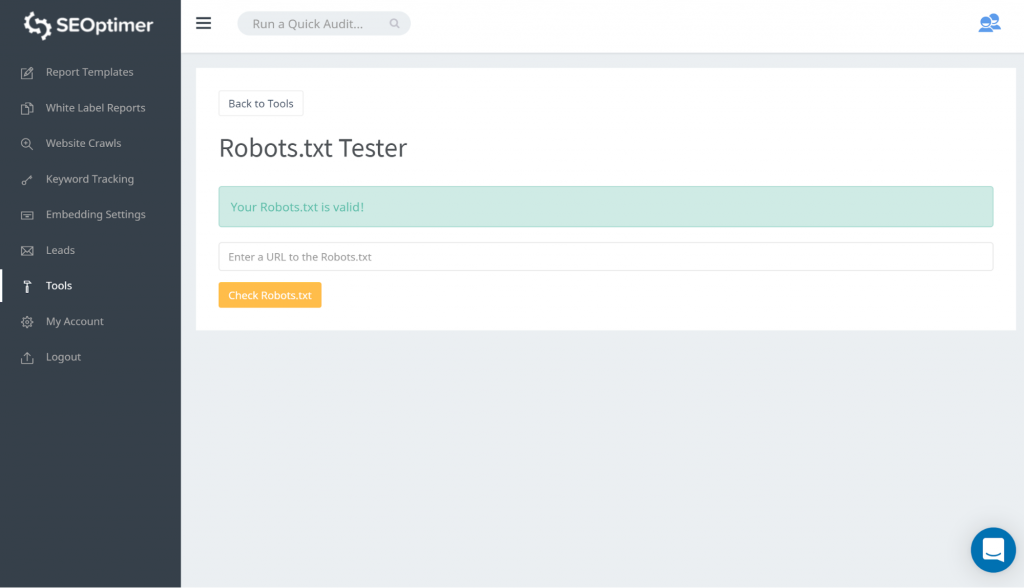
robots.txt dosyanızı test etmenin bir yolu, robots.txt tester kullanmaktır. Engellenen şeylerin 'engelli' kalmasından memnun olduğunuzu fark edebilirsiniz. Bu nedenle, herhangi bir işlem yapmanız gerekmez.
Ayrıca bu GSC bağlantısını takip edebilirsiniz. Sonra şunları yapmanız gerekiyor:
- Engellenen kaynakların listesini açın ve alan adını seçin.
- Her kaynağa tıklayın. Bu açılır pencereyi görmelisiniz:
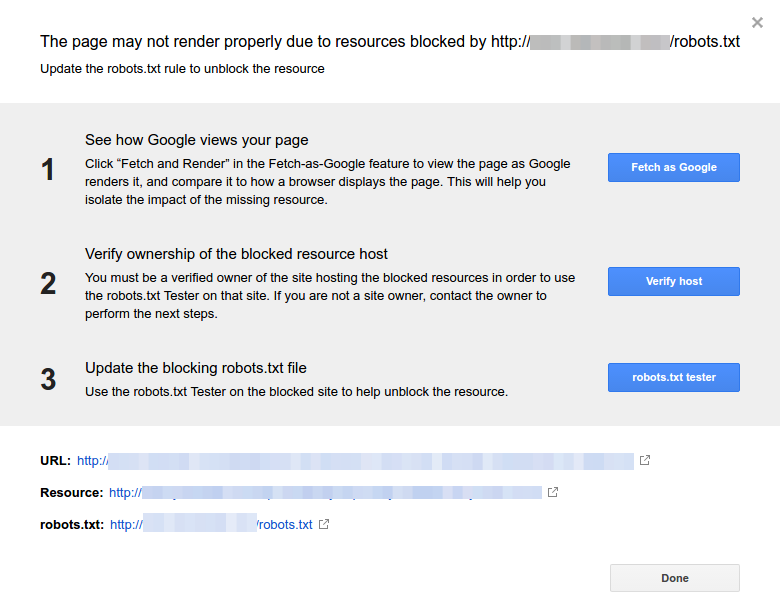
Bildirimin nedenini belirleyin
Bildirim birkaç nedenden kaynaklanabilir. İşte yaygın olanlar:
Ancak öncelikle, sayfaların robots.txt tarafından engellenmesi mutlaka bir sorun değildir. Geliştiricinin gereksiz / kategori sayfalarını veya yinelenenleri engellemek istemesi gibi nedenlerle tasarlanmış olabilir. Peki, tutarsızlıklar nelerdir?
Yanlış URL Formatı
Bazen, sorun gerçekten bir sayfa olmayan bir URL'den kaynaklanabilir. Örneğin, URL https://www.seoptimer.com/?s=digital+marketing ise, URL'nin hangi sayfaya çözümlendiğini bilmek gereklidir.
Eğer gerçekten kullanıcılarınızın görmesi gereken önemli içerikler içeren bir sayfa ise, o zaman URL'yi değiştirmeniz gerekiyor. Bu, bir sayfanın slug'ını düzenleyebileceğiniz Wordpress gibi İçerik Yönetim Sistemleri (CMS) üzerinde mümkündür.
Eğer sayfa önemli değilse ya da /?s=digital+marketing örneğimizde olduğu gibi blogumuzdan bir arama sorgusuysa, GSC hatasını düzeltmeye gerek yoktur.
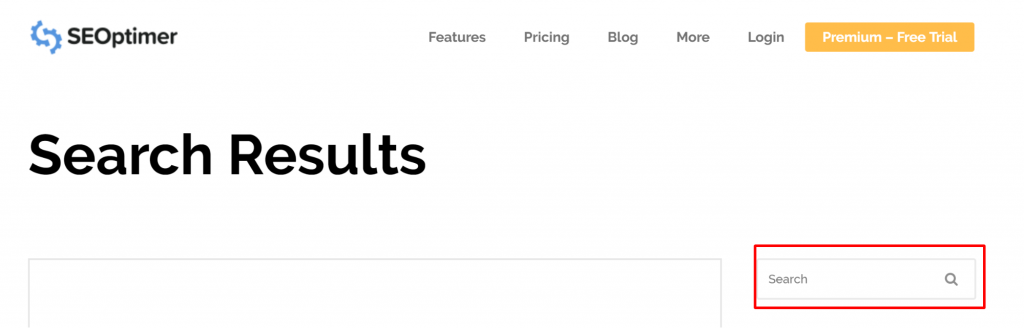
İndekslenmiş olup olmaması fark etmez, çünkü bu gerçek bir URL değil, bir arama sorgusudur. Alternatif olarak, sayfayı silebilirsiniz.
Dizinlenmesi Gereken Sayfalar
İndekslenmesi gereken sayfaların indekslenmemesinin birkaç nedeni vardır. İşte birkaçı:
- Robot direktiflerinizi kontrol ettiniz mi? Örneğin, etiketler ve kategoriler gibi aslında indekslenmesi gereken sayfaların indekslenmesini engelleyen direktifler içeren bir robots.txt dosyası eklemiş olabilirsiniz. Etiketler ve kategoriler, sitenizdeki gerçek URL'lerdir.
- Googlebot'u bir yönlendirme zincirine mi işaret ediyorsunuz? Googlebot, karşılaştıkları her bağlantıyı takip eder ve indeksleme için okumak üzere ellerinden gelenin en iyisini yaparlar. Ancak, çoklu, uzun, derin bir yönlendirme ayarladıysanız veya sayfa sadece ulaşılamaz durumadaysa, Googlebot aramayı bırakacaktır.
- Kanonik bağlantıyı doğru bir şekilde uyguladınız mı? Kanonik etiket, yinelenen içerik durumunda Googlebot'a tercih edilen ve kanonik sayfanın hangisi olduğunu söylemek için HTML başlığında kullanılır. Her sayfanın bir kanonik etiketi olmalıdır. Örneğin, İspanyolca'ya çevrilmiş bir sayfanız var. İspanyolca URL'yi kendiniz kanonik yapacak ve sayfayı varsayılan İngilizce versiyonunuza kanonik olarak geri bağlamak isteyeceksiniz.
WordPress'te Robots.txt dosyanızın doğru olduğunu nasıl doğrularsınız?
WordPress için, robots.txt dosyanız site kurulumunun bir parçasıysa, onu düzenlemek için Yoast Eklentisini kullanın. Sorun yaratan robots.txt dosyası sizin olmayan başka bir siteye aitse, site sahipleriyle iletişime geçmeniz ve robots.txt dosyalarını düzenlemelerini rica etmeniz gerekmektedir.
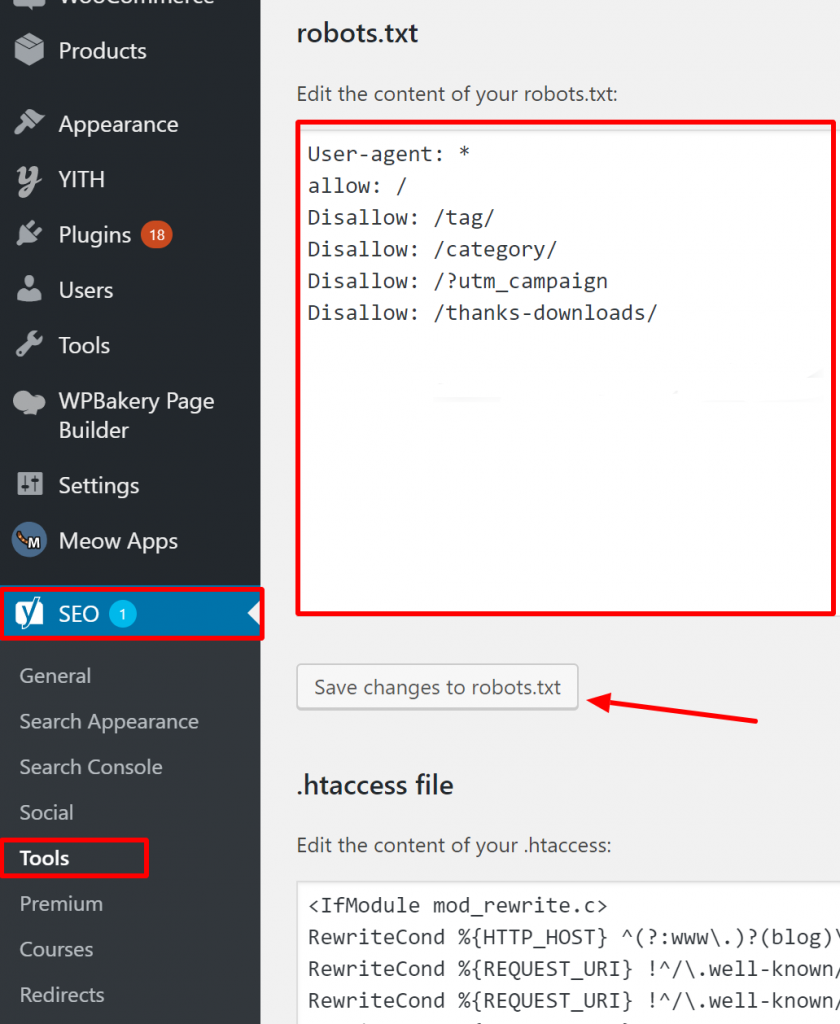
İndekslenmemesi Gereken Sayfalar
İndekslenmemesi gereken sayfaların indekslenme sebepleri birkaçtır. İşte birkaçı:
Robots.txt direktifleri bir sayfanın indekslenmemesi gerektiğini ‘söyler’. Sayfanın indekslenmemesi gerektiğini arama motoru botlarının ‘bilsinler’ diye, ‘noindex’ direktifi ile izin verilmiş sayfanın taramaya izin verilmesi gerektiğini unutmayın.
robots.txt dosyanızda şu hususlara dikkat edin:
- ‘Disallow’ satırı hemen ‘user-agent’ satırının ardından gelmiyor.
- Bir ‘user-agent’ bloğundan fazlası yok.
- Görünmez Unicode karakterler - robots.txt dosyanızı, özel karakterleri kaldıracak kodlamaları dönüştürecek bir metin düzenleyici ile çalıştırmanız gerekiyor.
Diğer sitelerden sayfalara bağlantı verilmiştir. Sayfalar, robots.txt dosyasında engellenmiş olsalar bile diğer sitelerden bağlantı verilerek indekslenebilir. Ancak bu durumda, arama motoru sonuçlarında sadece URL ve çapa metni görünür. İşte bu URL'lerin arama motoru sonuç sayfasında (SERP) görüntülenme şekli:
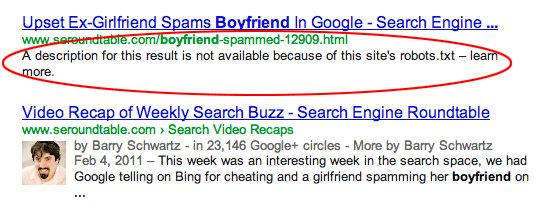 görsel kaynağı Webmasters StackExchange
görsel kaynağı Webmasters StackExchange
robots.txt engelleme sorununu çözmenin bir yolu, sunucunuzdaki dosya(lar)ı şifre ile korumaktır.
Alternatif olarak, sayfaları robots.txt dosyasından silin veya engellemek için aşağıdaki meta etiketini kullanın
onlar:
<meta name=”robots” content=”noindex”>
Eski URL'ler
Yeni içerik veya yeni bir site oluşturduysanız ve bunun indekslenmemesi için robots.txt'de ‘noindex’ direktifini kullandıysanız veya yakın zamanda GSC için kaydolduysanız, robots.txt tarafından engellenme sorununu çözmek için iki seçeneğiniz vardır:
- Google'ın eski URL'leri indeksinden zamanla çıkarmasına zaman verin
- Eski URL'leri güncel olanlara 301 yönlendirmesi yapın
İlk durumda, eğer tüm yapabildikleri 404 döndürmekse (bu sayfaların mevcut olmadığı anlamına gelir), Google sonunda URL'leri dizininden çıkarır. 404'lerinizi yönlendirmek için eklentiler kullanmak tavsiye edilmez. Eklentiler, GSC'nin size ‘robots.txt tarafından engellendi’ uyarısını göndermesine neden olabilecek sorunlara yol açabilir.
Sanal robots.txt dosyaları
Bir robots.txt dosyanız olmasa bile bildirim alma ihtimali vardır. Bunun nedeni, örneğin WordPress gibi CMS (Müşteri Yönetim Sistemleri) tabanlı sitelerin sanal robots.txt dosyalarına sahip olmasıdır. Eklentiler de robots.txt dosyaları içerebilir. Bunlar, sitenizde sorunlara neden olan dosyalar olabilir.
Bu sanal robots.txt dosyaları kendi robots.txt dosyanızla üzerine yazılmalıdır. Robots.txt dosyanızın, tüm arama motoru botlarının sitenizi taramasına izin veren bir yönerge içerdiğinden emin olun. Bu, hangi URL'lerin indeksleneceğini veya indekslenmeyeceğini belirleyebilmelerinin tek yoludur.
İşte tüm botların sitenizi taramasına izin veren yönerge:
User-agent: *
Yasakla: /
‘Hiçbir şeyi yasaklama’ anlamına gelir.
Sonuç olarak
‘Indexed, though blocked by robots.txt warning’ uyarısını, ne anlama geldiğini, etkilenen sayfaların veya URL'lerin nasıl tespit edileceğini ve uyarının arkasındaki sebebi inceledik. Ayrıca nasıl düzeltileceğine de baktık. Uyarının sitenizde bir hata anlamına gelmediğini unutmayın. Ancak, düzeltilmemesi en önemli sayfalarınızın indekslenmemesine yol açabilir ki bu da kullanıcı deneyimi için iyi değildir.